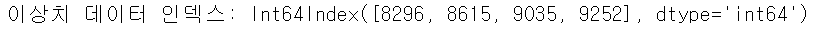class sklearn.linear_model.LinearRegression(fit_intercept=True, normalize=False, copy_X=True, n_jobs=1)
○ LinearRegression 클래스는 실제값과 예측값의 RSS를 최소화해 OLS(Ordinary Least Squares; 최소 제곱법) 추정 방식으로 구현한 클래스
○ 주요 입력 파라미터
- fit_intercept: w0(절편, bias) 값을 계산할 것인지 말지를 지정. 만일 False로 지정하면 절편이 사용되지 않고 0으로 지정됨
- normalize: 회귀를 수행하기 전에 입력 데이터 세트를 정규화할 것인지 결정(사용 x, 전처리 과정에서 스케일링 진행 → 디폴트로 나둠)
○ 주요 속성
- coef_: 회귀계수가 배열 형태로 저장
- intercept_: w0(절편, bias)값
선형 회귀의 다중 공선성 문제
선형 회귀와 같은 OLS 기반의 회귀 계수를 계산하는 회귀 모델은 입력 피처의 독립성에 많은 영향을 받는다. 즉, 피처간의 상관관계가 매우 높은 경우 분산이 매우 커져서 오류에 민감해진다. 이를 다중 공선성(multi-collinearity)라고 한다.
일반적으로 상관관계가 높은 피처가 많은 경우 독립적인 중요한 피처만 남기고 제거하거나 규제를 적용한다.
회귀 평가 지표
"실제값과 예측값의 차이를 기반"
→ 실제값과 예측값의 차이를 그냥 더하면 +와 -가 섞여서 오류가 상쇄되서 정확한 지표가 될 수 없기 때문에 오류의 절대값 평균이나 제곱의 평균, 또는 제곱한 뒤 루트를 씌운 평균값을 구함
→ 실제값과 예측값의 차이, 다시 말해 오류가 작을수록 좋은 평가 결과이기 때문에 평가 지표가 작을수록 좋은 결과임
R^2은 설명력으로 회귀모델이 데이터를 얼마나 잘 설명하는지를 나타냄
mean_squared_error() 함수는 squared 파라미터가 기본적으로 True이다. 즉 MSE는 사이킷런에서 mean_squared_error(실제값, 예측값, squared=True)이며 RMSE는 mean_squared_error(실제값, 예측값, squared=False)를 이용해 구하지만 헷갈리기 때문에 RMSE를 구할때는 MSE에 np.sqrt()를 이용해 구하자!
사이킷런 scoring 함수에 회귀 평가 적용 시 유의 사항
cross_val_score, GridSearchCV와 같은 scoring 함수에 회귀 평가 지표를 적용할 때 유의 사항이 있다.
'neg_'라는 접두어가 붙어있는데 이는 Negative(음수)를 의미하며, 기존의 회귀 평가 지표 값에 음수(-1)를 곱한다는 의미이다. 이렇게 'neg_'가 붙는 이유는 사이킷런의 scoring 함수가 score값이 클수록 좋은 평가 결과로 평가하기 때문이다. 하지만 실제값과 예측값의 차이를 기반으로 하는 회귀 평가 지표의 경우 값이 커지면 오히려 나쁜 모델이라는 의미이므로 음수(-1)를 곱해주는 것이다.
경사 하강법은 비용함수 RSS를 최소화하는 방법을 직관적으로 제공하는 뛰어난 방식으로, 점진적인 반복 계산을 통해 회귀계수를 업데이트하면서 오류값이 최소가 되는 회귀계수를 구하는 방법이다.
그렇다면 솔루션인 '경사 하강법'을 통해 어떻게 하면 오류가 작아지는 방향으로 회귀계수를 업데이트할 수 있을까?
→ 미분을 통해 비용함수의 최소값을 찾음(미분은 증가 또는 감소의 방향성을 나타냄)
비용함수를 보면 제곱을 했기 때문에 회귀계수에 대한 2차 함수로서 아래 그림과 같은 포물선 형태이다. 2차 함수의 최저점은 2차 함수의 미분값인 1차 함수의 기울기가 가장 최소일 때다.
경사 하강법은 비용함수를 최초의 회귀계수(w) 값에서부터 미분을 적용한 뒤, 이 미분 값(기울기)이 계속 감소하는 방향으로 순차적으로 회귀계수를 업데이트한다.마침내 더 이상 미분된 1차 함수의 기울기가 감소하지 않는 지점을 비용함수가 최소인 지점으로 간주하고, 그때의 회귀계수를 반환한다.
경사 하강법 수식 정리 및 파이썬 코드 구현
경사 하강법 수식 정리 전 알아야 할 'Chain Rule'
<경사 하강법 수식 정리>
1. 비용함수 RSS(w0, w1)을 편의상 R(w)로 지칭. R(w)를 미분해 미분 함수의 최소값을 구해야 하는데, R(w)는 두 개의 회귀계수인 w0와 w1을 각각 가지고 있기 때문에 일반적인 미분을 적용할 수 없고, w0, w1 각 변수에 편미분을 적용해야 한다.
2. w1, w0의 편미분 결과값을 반복적으로 보정하면서 w1, w0값을 업데이트하면 비용함수 R(w)가 최소가 되는 w1, w0값을 구할 수 있다.
이때, 편미분 값이 너무 클 수 있기 때문에 보정 계수 η를 곱하는데, 이를 '학습률'이라고 함
업데이트는 이전 회귀계수에서 편미분 결과값을 빼면서 적용함(아래와 같음)
→ 새로운 w1, 새로운 w0를 반복적으로 업데이트 하면서 비용함수가 최소가 되는 값을 찾음
경사 하강법의 프로세스를 정리를 하자면
<경사 하강법 파이썬 코드 구현>
● 실습을 위한 y=4x+6 시뮬레이션 데이터 생성(단순 선형회귀로 예측할 만한 데이터 생성)
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
np.random.seed(0)
noise = np.random.randn(100,1)
X = 2 * np.random.rand(100,1)
y = 6 + 4 * X + noise
plt.scatter(X, y)
● 경사하강법
# w1과 w0를 업데이트할 w1_update, w0_update를 반환하는 함수 생성
def get_weight_updates(w1, w0, X, y, learning_rate=0.01):
N = len(y)
# w1_update, w0_update를 먼저 w1, w0의 shape와 동일한 크기를 가진 0값으로 초기화
w1_update = np.zeros_like(w1)
w0_update = np.zeros_like(w0)
# 예측 배열 계산, 예측과 실제값의 차이 계산
y_pred = np.dot(X, w1.T) + w0
diff = y - y_pred
# w0_update를 dot 행렬 연산으로 구하기 위해 모두 1값을 가진 행렬 생성
w0_factors = np.ones((N,1))
# w1과 w0를 업데이트할 w1_update, w0_update 계산
w1_update = -(2/N) * learning_rate * (np.dot(X.T, diff))
w0_update = -(2/N) * learning_rate * (np.dot(w0_factors.T, diff))
return w1_update, w0_update
# get_weight_updates 함수를 이용해 경사 하강 방식으로 반복적으로 수행하여 w1, w0를 업데이트하는 함수 생성
# 입력 인자 iters로 주어진 횟수만큼 반복적으로 w1과 w0를 업데이트
def gradient_descent_steps(X, y, iters=10000):
# w0와 w1을 모두 0으로 초기화
w0 = np.zeros((1,1))
w1 = np.zeros((1,1))
# 인자로 주어진 iters만큼 반복적으로 get_weight_updates()를 호출해 w1, w0 업데이트 수행
for ind in range(iters):
w1_update, w0_update = get_weight_updates(w1, w0, X, y, learning_rate=0.01)
w1 = w1 - w1_update
w0 = w0 - w0_update
return w1, w0
● 비용함수(RSS) 값 계산, 회귀계수 계산
# 비용함수 정의
def get_cost(y, y_pred):
N = len(y)
cost = np.sum(np.square(y - y_pred)) / N
return cost
# 회귀계수 계산
w1, w0 = gradient_descent_steps(X, y, iters=1000)
print('w1:{0:.3f}, w0:{1:.3f}'.format(w1[0,0], w0[0,0]))
# 비용함수 값 계산
y_pred = w1[0,0] * X + w0
print('cost:{0:.4f}'.format(get_cost(y, y_pred)))
- 테스트 데이터(검증 데이터)에 특정 피처의 값들을 반복적으로 무작위로 섞은 뒤 모델 성능이 얼마나 저하되는지를 기준으로 해당 피처의 중요도를 산정
permutation importance 프로세스
●모델 학습 후 원본 테스트 데이터로 기준 평가 성능을 설정
●원본 테스트(검증) 데이터의 개별 feature 별로 아래 수행
설정된 iteration만큼 해당 feature 값들을 shuffle
각각 모델 성능 평가 후 평균
기준 평가 성능과 위에서 구한 평균을 비교해 모델 성능이 얼마나 저하되었는지 평가해서 피처 중요도 산정(중요한 피처면 저하가 큼) → 원본에서 평균적으로 얼마나 성능이 감소했나
# 실습을 위한 데이터 세트
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
diabetes = load_diabetes()
X_train, X_val, y_train, y_val = train_test_split(diabetes.data, diabetes.target, random_state=0)
# 모델 학습 및 R2 Score 평가(기준 평가 성능)
from sklearn.linear_model import Ridge # 사용할 모델
from sklearn.metrics import r2_score # 평가 척도
model = Ridge(alpha=1e-2).fit(X_train, y_train)
y_pred = model.predict(X_val)
print('r2 score:', r2_score(y_val, y_pred))
import numpy as np
# permutation_importance:원본 테스트(검증) 데이터 지정
from sklearn.inspection import permutation_importance
r = permutation_importance(model, X_val, y_val, n_repeats=30, random_state=0) # n_repeats:iteration 만큼 shuffle
for i in r.importances_mean.argsort()[::-1]: # 평균 permutation importance가 높은 순으로 인덱스를 내림차순 정렬
if r.importances_mean[i] -2 * r.importances_std[i] > 0: # 표준편차의 2 배 값보다 큰 평균을 가진 피처들로 선별
# 위 조건을 만족하는 피처들의 평균 permutation importance값과 표준편차 출력
print(diabetes.feature_names[i], " ", np.round(r.importances_mean[i], 4), ' +/-', np.round(r.importances_std[i], 5))
- 표준편차의 2 배 값보다 큰 평균을 가진 피처들로 선별했는가는 단순히 경험적인 결과이다. 일반적으로 permutation importance 사용할 때 경험적으로 표준편차의 2 배 값 정도를 추천하지만 꼭 2배일 필요는 없다. 2~3배 사이, 예를 들어 2.5배, 2.8배, 3배 정도의 기준을 가지고 feature selection을 적용한 뒤 가장 성능이 뛰어난 결과를 적용해 보면 된다.
- permutation_importance를 적용해 버리면, 바로 피처 중요도가 permutation importance 방식으로 적용해버린다. 그러니까, permutation_importance.importances_mean 속성은 계산된 피처 중요도를 가지고 있다. 이중에서 높은 것부터 출력이 된다. 즉, 위의 결과에서 각 피처의 importance_mean의 값을 보니 s5가 0.2042로 모델 성능이 가장 저하해서 가장 중요한 피처이다.
- feature 중요도가 낮은 속성들을 차례로 제거해 가면서 반복적으로 학습/평가를 수행하여 최적 feature 추출
- 수행시간이 오래 걸리고, 낮은 속성들을 제거해 나가는 메커니즘이 정확한 feature selection을 찾는 목표에 정확히 부합하지 않을 수 있음
# 실습을 위한 임의의 분류용 데이터 생성
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=1000, n_features=25, n_informative=3,
n_redundant=2, n_repeated=0, n_classes=8,
n_clusters_per_class=1, random_state=0)
# 피처들을 데이터프레임 형태로 만들어보자
import pandas as pd
columns_list = ['col1', 'col2', 'col3', 'col4', 'col5', 'col6', 'col7', 'col8', 'col9', 'col10', 'col11', 'col12', 'col13',
'col14', 'col15', 'col16', 'col17', 'col18', 'col19', 'col20', 'col21', 'col22', 'col23', 'col24', 'col25']
df_X = pd.DataFrame(X, columns=columns_list)
# RFE
from sklearn.feature_selection import RFE
from sklearn.svm import SVC # 사용할 모델
svc = SVC(kernel='linear')
rfe = RFE(estimator=svc, n_features_to_select=5, step=1) # step=1: 하나씩 피처 제거, n_features_to_select=5: 5개 피처를 선택
rfe.fit(X, y)
print(rfe.support_) # 선택된 피처는 True로 반환
print('선택된 피처:', df_X.columns[rfe.support_])
# 선택된 피처를 통한 최종 데이터프레임 생성
feature_selection = df_X.columns[rfe.support_]
df_X = df_X[feature_selection]
df = df_X # 데이터프레임 이름 변경
df['target'] = y
df.head()
○ RFECV(Recursive Feature Elimination with Cross Validation)
- RFECV는 RFE와 로직은 똑같지만, 각 feature 개수마다 교차검증을 활용해 각 feature 개수별 성능을 평균내어 가장 높은 성능을 가지는 feature 개수에 해당하는 feature들을 최종 feature selection 결과로 사용
→ 몇 개의 피처가 최적일지 알 수 있음
# 실습을 위한 임의의 분류용 데이터 생성
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=1000, n_features=25, n_informative=3,
n_redundant=2, n_repeated=0, n_classes=8,
n_clusters_per_class=1, random_state=0)
# 피처들을 데이터프레임 형태로 만들어보자
import pandas as pd
columns_list = ['col1', 'col2', 'col3', 'col4', 'col5', 'col6', 'col7', 'col8', 'col9', 'col10', 'col11', 'col12', 'col13',
'col14', 'col15', 'col16', 'col17', 'col18', 'col19', 'col20', 'col21', 'col22', 'col23', 'col24', 'col25']
df_X = pd.DataFrame(X, columns=columns_list)
# RFECV
from sklearn.feature_selection import RFECV
from sklearn.model_selection import StratifiedKFold
from sklearn.svm import SVC # 사용할 모델
svc = SVC(kernel='linear')
rfecv = RFECV(estimator=svc, step=1, cv=StratifiedKFold(3), scoring='accuracy')
rfecv.fit(X, y)
# 몇 개의 피처가 최적일지 교차검증 성능 시각화
import matplotlib.pyplot as plt
plt.figure()
plt.xlabel('Number of features selected')
plt.ylabel('Cross validation score')
plt.plot(range(1, len(rfecv.grid_scores_) + 1), rfecv.grid_scores_)
plt.show() # cv를 3으로 해서 3개의 그래프가 나옴
# 0~5 사이에 특정 값이 최적의 피처 개수인듯
# 선택된 피처를 통한 최종 데이터프레임 생성
feature_selection = df_X.columns[rfecv.support_]
df_X = df_X[feature_selection]
df = df_X # 데이터프레임 이름 변경
df['target'] = y
df.head()
○ SelectFromModel
- 모델 최초 학습 후 선정된 feature 중요도에 따라 평균/중앙값 등의 특정 비율 이상인 feature들을 선택
(이 비율은 threshold로 지정)
# 실습을 위한 데이터 세트
from sklearn.datasets import load_diabetes
diabetes = load_diabetes()
X = diabetes.data
y = diabetes.target
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LassoCV # 사용할 모델
lasso = LassoCV()
lasso.fit(X,y) # 모델 학습
# 회귀계수 절대값 시각화
importance = np.abs(lasso.coef_)
plt.bar(height=importance, x=diabetes.feature_names)
plt.title('feature importances via coefficients')
plt.show()
# selectfrommodel
from sklearn.feature_selection import SelectFromModel
threshold = np.sort(importance)[-3] + 0.01 # 회귀계수가 3번째로 큰 값에 0.01을 더해서 threshold 지정하기로 결정
sfm = SelectFromModel(lasso, threshold=threshold)
sfm.fit(X,y)
print(sfm.threshold_) # threshold 값
print(sfm.get_support()) # 선택된 피처는 True로 반환
print('선택된 피처:', np.array(diabetes.feature_names)[sfm.get_support()])
사이킷런의 Recursive Feature Elimination이나 SelectFromModel의 경우 트리기반의 분류에서는 Feature importance, 회귀에서는 회귀 계수를 기반으로 반복적으로 모델 평가하면서 피처들을 선택하는 방식인데, 이런 방식의 Feature Selection은 오히려 모델의 성능을 떨어뜨릴 가능성이 높다. 그러니까 정확하지 않은 feature selection 방법이다.
개별 알고리즘의 예측 결과 데이터 세트를 최종적인 메타 데이터 세트로 만들어 별도의 ML 알고리즘으로 최종 학습을 수행하고 테스트 데이터를 기반으로 다시 최종 예측을 수행하는 방식
→기반 모델들이 예측한 값들을 Stacking 형태로 만들어서 메타 모델이 이를 학습하고 예측하는 모델
●스태킹 모델은 다음과 같은 두 종류의 모델이 필요함
개별적인 기반 모델
이 개별 기반 모델의 예측 데이터를 학습 데이터로 만들어서 학습하는 최종 메타 모델
즉, 스태킹 모델은 여러 개별 모델의 예측 데이터를 각각 스태킹 형태로 결합해 최종 메타 모델의 학습용 피처 데이터 세트와 테스트용 피처 데이터 세트를 만드는 것
기본 스태킹
# 필요한 모듈 불러오기
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 데이터 로드
cancer_data = load_breast_cancer()
X_data = cancer_data.data
y_label = cancer_data.target
# 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X_data, y_label, test_size=0.2, random_state=0)
# 개별 ML 모델 생성
knn_clf = KNeighborsClassifier(n_neighbors=4)
rf_clf = RandomForestClassifier(n_estimators=100, random_state=0)
dt_clf = DecisionTreeClassifier()
ada_clf = AdaBoostClassifier(n_estimators=100)
# 스태킹으로 만들어진 데이터 세트를 학습, 예측할 최종 모델
lr_final = LogisticRegression()
# 개별 ML 모델 학습
knn_clf.fit(X_train, y_train)
rf_clf.fit(X_train, y_train)
dt_clf.fit(X_train, y_train)
ada_clf.fit(X_train, y_train)
# 개별 ML 모델 예측
knn_pred = knn_clf.predict(X_test)
rf_pred = rf_clf.predict(X_test)
dt_pred = dt_clf.predict(X_test)
ada_pred = ada_clf.predict(X_test)
# 개별 ML 모델의 정확도 확인
print('KNN 정확도:{0:.4f}'.format(accuracy_score(y_test, knn_pred)))
print('랜덤 포레스트 정확도:{0:.4f}'.format(accuracy_score(y_test, rf_pred)))
print('결정트리 정확도:{0:.4f}'.format(accuracy_score(y_test, dt_pred)))
print('에이다부스트 정확도:{0:.4f}'.format(accuracy_score(y_test, ada_pred)))
# 개별 ML 모델의 예측 결과를 피처로 만듬
pred = np.array([knn_pred, rf_pred, dt_pred, ada_pred]) # 예측 결과를 행 형태로 붙임
print(pred.shape)
pred = np.transpose(pred) # transpose를 이용해 행과 열의 위치 교환. 컬럼별로 각 알고리즘의 예측 결과를 피처로 만듬
print(pred.shape)
# 최종 메타 모델인 로지스틱 회귀 학습/예측/평가
lr_final.fit(pred, y_test)
final = lr_final.predict(pred)
print('최종 메타 모델의 예측 정확도:{0:.4f}'.format(accuracy_score(y_test, final)))
메타 모델인 로지스틱 회귀 기반에서 최종 학습할 때 레이블 데이터 세트로 학습 데이터가 아닌 테스트용 레이블 데이터 세트를 기반으로 학습했기에 과적합 문제가 존재 → 과적합을 개선하기 위한 'CV 세트 기반의 스태킹'
CV 세트 기반의 스태킹
개별 모델들이 각각 교차검증으로 메타 모델을 위한 학습용 스태킹 데이터 생성과 예측을 위한 테스트용 스태킹 데이터를 생성한 뒤 이를 기반으로 메타 모델이 학습과 예측을 수행한다.
이해를 돕기 위해 다음과 같이 2단계의 스텝으로 구분하자.
Step1: 각 모델별로 원본 학습/테스트 데이터를 예측한 결과값을 기반으로 메타 모델을 위한 학습용/테스트용 데이터를 생성
Step2: Step1에서 개별 모델들이 생성한 학습용 데이터를 모두 스태킹 형태로 합쳐서 메타 모델이 학습할 최종 학습용 데이터 세트를 생성함. 마찬가지로 각 모델들이 생성한 테스트용 데이터를 모두 스태킹 형태로 합쳐서 메타 모델이 예측할 최종 테스트 데이터 세트를 생성함. 메타 모델은 최종적으로 생성된 학습 데이터 세트와 원본 학습 데이터의 레이블 데이터를 기반으로 학습한 뒤, 최종적으로 생성된 테스트 데이터 세트를 예측하고, 원본 테스트 데이터의 레이블 데이터를 기반으로 평가함
Step1의 과정을 도식화해서 로직을 알아보자.
●Step1
from sklearn.model_selection import KFold
# 개별 기반 모델에서 최종 메타 모델이 사용할 학습 및 테스트용 데이터를 생성하기 위한 함수 생성
def get_stacking_base_datasets(model, X_train_n, y_train_n, X_test_n, n_folds):
kf = KFold(n_splits=n_folds, shuffle=False) # ,random_state=0) # Default shuffle=False
# 추후에 메타 모델이 사용할 학습 데이터 반환을 위한 넘파이 배열 초기화
train_fold_pred = np.zeros((X_train_n.shape[0], 1)) # 2차원, np.zeros((a,b))
test_pred = np.zeros((X_test_n.shape[0], n_folds)) # 2차원
print(model.__class__.__name__, 'model 시작')
for folder_counter, (train_index, valid_index) in enumerate(kf.split(X_train_n)):
# 입력된 학습 데이터에서 기반 모델이 학습/예측할 폴드 데이터 세트 추출
X_tr = X_train_n[train_index]
y_tr = y_train_n[train_index]
X_te = X_train_n[valid_index]
# 폴드 세트 내부에서 다시 만들어진 학습 데이터로 기반 모델의 학습 수행
model.fit(X_tr, y_tr)
# 폴드 세트 내부에서 다시 만들어진 검증 데이터로 기반 모델에서 예측 후 데이터 저장
train_fold_pred[valid_index, :] = model.predict(X_te).reshape(-1, 1) # 2차원, reshape로 1차원에서 2차원으로 변경
# 입력된 원본 테스트 데이터를 폴드 세트내 학습된 기반 모델에서 예측 후 데이터 저장
test_pred[:, folder_counter] = model.predict(X_test_n)
# 폴드 세트 내에서 원본 테스트 데이터를 예측한 데이터를 평균하여 테스트 데이터로 생성
test_pred_mean = np.mean(test_pred, axis=1).reshape(-1, 1) # 2차원, reshape로 1차원에서 2차원으로 변경
# train_fold_pred는 최종 메타 모델이 사용하는 학습 데이터, test_pred_mean은 테스트 데이터
return train_fold_pred, test_pred_mean
# 인자로 입력받은 DataFrame을 복사한 뒤 Time 피처만 삭제하고 복사된 DataFrame 반환하는 함수 생성
def get_preprocessed_df(df=None):
df_copy = df.copy()
df_copy.drop('Time', axis=1, inplace=True)
return df_copy
●학습 / 테스트 데이터 세트 분리
stratify 방식 사용: 불균형 데이터 세트이므로 학습 / 테스트 데이터 세트는 원본 데이터와 같은 레이블 값 분포로 맞춰주고 → 학습 / 테스트 데이터 세트의 레이블 값 분포를 동일하게 설정
from sklearn.model_selection import train_test_split
# 사전 데이터 가공 후 학습과 테스트 데이터 세트를 반환하는 함수 생성
def get_train_test_dataset(df=None):
# Time 피처를 삭제한 df를 받아옴
df_copy = get_preprocessed_df(df)
# 피처, 레이블 분리
X_features = df_copy.iloc[:, :-1]
y_target = df_copy.iloc[:, -1]
# 학습 데이터 세트, 테스트 데이터 세트 분리
X_train, X_test, y_train, y_test = train_test_split(X_features, y_target, test_size=0.3, random_state=0, stratify=y_target)
return X_train, X_test, y_train, y_test
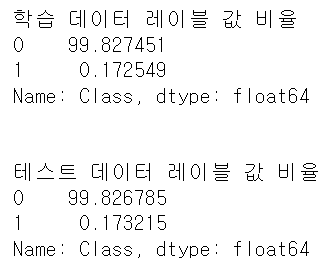
LightGBM 2.1.0 이상의 버전에서 boost_from_average 파라미터의 default가 False에서 True로 변경됨. 레이블 값이 극도로 불균형한 분포를 이루는 경우 boost_from_average=True 설정은 재현율 및 ROC-AUC 성능을 매우 크게 저하시킴. 따라서 레이블 값이 극도로 불균형할 경우 boost_from_average를 False로 설정하는 것이 유리
# 본 데이터 세트는 극도로 불균형한 레이블 값 분포도를 가지므로 boost_from_average=False로 설정
from lightgbm import LGBMClassifier
lgbm_clf = LGBMClassifier(n_estimators=1000, num_leaves=64, n_jobs=-1, boost_from_average=False)
get_model_train_eval(lgbm_clf, ftr_train=X_train, ftr_test=X_test, tgt_train=y_train, tgt_test=y_test)
3. 데이터 분포도 변환 후 모델 학습/예측/평가
왜곡된 분포도를 가지는 데이터를 재가공한 뒤에 모델을 다시 테스트 해보자
●Amount 피처 분포도 확인
Amount 피처는 신용 카드 사용 금액으로 정상/사기 트랜잭션을 결정하는 매우 중요한 피처일 가능성이 높다.
모든 피처들의 이상치를 검출하는 것은 시간이 많이 소모되며, 결정값과 상관성이 높지 않은 피처들의 경우는 이상치를 제거하더라도 크게 성능 향상에 기여하지 않기 때문에 매우 많은 피처가 있을 경우 이들 중 결정값과 가장 상관성이 높은 피처들을 위주로 이상치를 검출하는 것이 좋다.
상관관계 히트맵에서 Class와 음의 상관관계가 가장 높은 V14, V17 중 V14에 대해서만 이상치를 찾아서 제거해보자
# 이상치 데이터 검출
import numpy as np
def get_outlier(df=None, column=None, weight=1.5):
quantile_25 = np.percentile(df[column].values, 25)
quantile_75 = np.percentile(df[column].values, 75)
iqr = quantile_75 - quantile_25
iqr_weight = iqr * weight
lowest = quantile_25 - iqr_weight
highest = quantile_75 + iqr_weight
# 최소와 최대 사이에 있지 않은 값은 이상치로 간주하고 인덱스 반환
outlier_index = df[column][(df[column] < lowest) | (df[column] > highest)].index
return outlier_index
outlier_index = get_outlier(df=card_df, column='V14', weight=1.5)
print('이상치 데이터 인덱스:', outlier_index)
print('이상치 데이터 개수:', len(outlier_index))
현재 creditcard 데이터는 전체 데이터를 기반으로 IQR을 설정하면 너무 많은 데이터가 이상치로 설정되서 삭제되는 범위가 너무 커짐
일반적으로 이상치가 이렇게 많다는 것은 말이 안된다고 판단, 그리고 이상치 제거는 가능한 최소치로 해줘야함
전체 데이터를 IQR로 하면 실제 사기 데이터에 잘 동작하는 데이터도 삭제 시켜버리고 있음
→creditcard 데이터(레이블이 불균형한 분포를 가진 불균형한 데이터)를 통해 생성한 모델은 실제값 0을 0으로 예측하는 것은 기본적으로 잘됨. 하지만 카드 사기 검출 모델에서 중요한 것은 실제 사기 즉 1을 1로 예측하는 것이 중요하므로 타겟값이 1인 데이터에 대해서 적절한 이상치를 제거하는 것이 필요함. 때문에 현재 데이터에서는 1의 데이터만 일정 수준에서 이상치를 제거해 주는게 좋음
# 타겟값이 1인 데이터에 대해서 이상치 데이터 검출
import numpy as np
def get_outlier(df=None, column=None, weight=1.5):
fraud = df[df['Class']==1][column]
quantile_25 = np.percentile(fraud, 25)
quantile_75 = np.percentile(fraud, 75)
iqr = quantile_75 - quantile_25
iqr_weight = iqr * weight
lowest = quantile_25 - iqr_weight
highest = quantile_75 + iqr_weight
# 최소와 최대 사이에 있지 않은 값은 이상치로 간주하고 인덱스 반환
outlier_index = fraud[(fraud < lowest) | (fraud > highest)].index
return outlier_index
outlier_index = get_outlier(df=card_df, column='V14', weight=1.5)
print('이상치 데이터 인덱스:', outlier_index)
# 이상치 데이터 제거
def get_preprocessed_df(df=None):
df_copy = df.copy()
# Amount 피처를 로그변환
amount_n = np.log1p(df_copy['Amount'])
# 변환된 Amount 피처를 Amount_Scaled로 피처명 변경후 DataFrame 맨 앞 컬럼으로 추가
df_copy.insert(0, 'Amount_Scaled', amount_n)
# 기존 Time, Amount 피처 삭제
df_copy.drop(['Time', 'Amount'], axis=1, inplace=True)
# 이상치 데이터 삭제하는 로직 추가
outlier_index = get_outlier(df=df_copy, column='V14', weight=1.5)
df_copy.drop(outlier_index, axis=0, inplace=True)
return df_copy
재샘플링, 즉 오버 샘플링 및 언더 샘플링을 적용시 올바른 평가를 위해 반드시 학습 데이터 세트에만 적용해야함
●SMOTE 오버 샘플링 적용
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=0)
X_train_over, y_train_over = smote.fit_resample(X_train, y_train) # X_train, y_train은 4번 과정까지 전처리 된 후 split된 데이터
# 데이터 확인
print('SMOTE 적용 전 학습용 데이터 세트:', X_train.shape, y_train.shape)
print('SMOTE 적용 후 학습용 데이터 세트:', X_train_over.shape, y_train_over.shape)
print('SMOTE 적용 후 레이블 값 분포')
print(pd.Series(y_train_over).value_counts())
threshold가 0.99 이하에서는 재현율이 매우 좋고, 정밀도가 극단적으로 낮다가 0.99 이상에서는 반대로 재현율이 대폭 떨어지고 정밀도가 높아짐. threshold를 조정하더라도 threshold의 민감도가 너무 심해 올바른 재현율/정밀도 성능을 얻을 수 없으므로 로지스틱 회귀 모델의 경우 SMOTE 적용 후 올바른 예측 모델이 생성되지 못했음.
LightGBM의 모델 성능 결과를 보면, 재현율은 증가했지만 정밀도가 감소했음을 알 수 있음. 이처럼 SMOTE를 적용하면 재현율은 높아지나, 정밀도는 낮아지는 것이 일반적임. 때문에 정밀도 지표보다 재현율 지표를 높이는 것이 중요한 업무에서SMOTE를 사용하면 좋음!