캐글의 산탄데르 고객 만족 데이터 세트에 대해서 고객 만족 여부를 XGBoost와 LightGBM을 활용해 예측한다.
데이터 세트에서 feature는 370개로 구성되며, 클래스 레이블 명은 TARGET이다.
TARGET=1 → 불만 고객
TARGET=0 → 만족 고객
이 데이터 세트는 불균형 데이터 세트이므로 모델의 성능 평가는 정확도가 아닌 roc_auc가 더 적합하다.
1. Data load and EDA
●필요한 모듈 및 패키지 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
import warnings
warnings.filterwarnings('ignore')●데이터 로드
cust_df = pd.read_csv(r"C:\Users\82102\PerfectGuide\4장\train_santander.csv", encoding='latin-1')
cust_df.head()cust_df.shape
cust_df.info()
cust_df.isnull().sum()

sum(cust_df.isnull().sum()==1)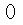
- 370개의 feature, 1개의 class 컬럼으로 구성
- 111개의 float형 feature, 260개의 int형 feature로 모든 feature가 숫자형
- 결측값은 없음
●클래스 비율 확인
cust_df['TARGET'].value_counts()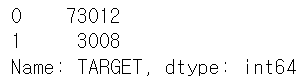
print('만족 비율:', cust_df['TARGET'].value_counts()[0] / cust_df.shape[0])
print('불만족 비율:', cust_df['TARGET'].value_counts()[1] / cust_df.shape[0])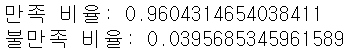
- 대부분이 만족이며 불만족인 고객은 약 4%에 불과 → 불균형 데이터 세트
●각 피처의 분포 확인
cust_df.describe()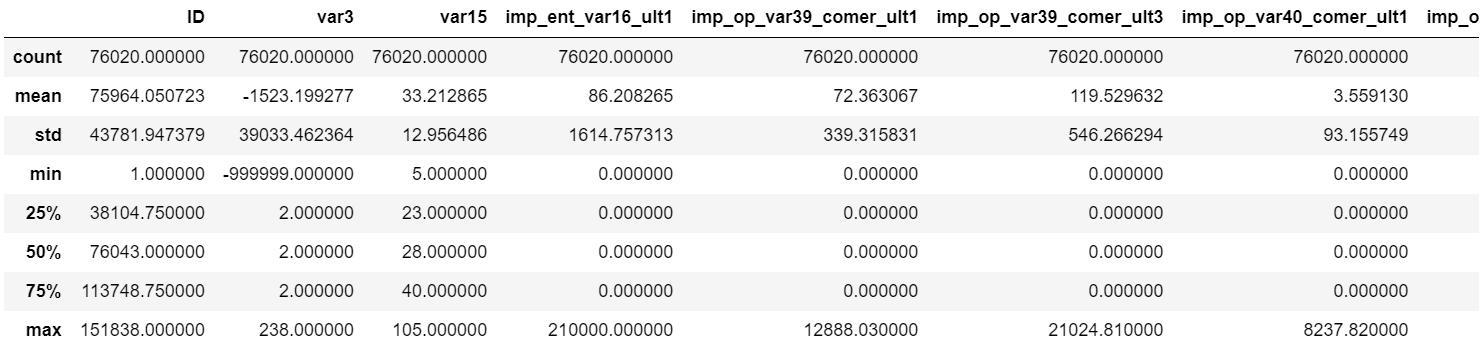
var3 컬럼의 경우 min 값이 -999999이다. 이 값은 NaN이나 특정 예외 값을 -999999로 변환한 것으로 보인다.
2. Preprocessing
●위에서 문제가 있던 var3 컬럼의 값 분포 확인
cust_df['var3'].value_counts()
-999999 값이 116개가 존재하고 다른 값에 비해서 편차도 심함 → 가장 값이 많은 2로 변환하기로 결정
●var3 컬럼 -999999 값을 가장 값이 많은 2로 변환
cust_df['var3'].replace(-999999, 2, inplace=True)●ID 피처는 단순 식별자에 불과하므로 드롭
cust_df.drop('ID', axis=1, inplace=True)●피처와 클래스 분리
X_features = cust_df.iloc[:, :-1]
y_labels = cust_df.iloc[:, -1]●학습 데이터 세트와 테스트 데이터 세트로 분리(불균형 데이터 세트이므로 stratify를 이용해 학습 데이터 세트와 테스트 데이터 세트의 클래스 비율을 원본 데이터의 클래스 비율과 유사하게 맞춰주기로 결정)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_features, y_labels, test_size=0.2, stratify=y_labels, random_state=0)# 학습 데이터, 테스트 데이터 target 값 분포 확인
print('학습 데이터 세트 target 값 분포')
print(y_train.value_counts() / y_train.shape[0])
print('\n')
print('테스트 데이터 세트 target 값 분포')
print(y_test.value_counts() / y_test.shape[0])
- 학습과 테스트 데이터 세트 target의 분포가 비슷하게 추출됐고, 이 분포는 원본 데이터와 유사하게 추출됨
● XGBoost, LightGBM의 early stopping을 사용하기 위해 X_train, y_train을 다시 학습과 검증 데이터 세트로 분리
(마찬가지로 stratify를 이용하기로 결정)
# X_train, y_train을 다시 학습과 검증 데이터 세트로 분리
X_tr, X_val, y_tr, y_val = train_test_split(X_train, y_train, test_size=0.3, stratify=y_train, random_state=0)3. XGBoost Model
●대략적인 모델의 성능을 확인해보자
from xgboost import XGBClassifier
from sklearn.metrics import roc_auc_score
# n_estimators=500, learning_rate=0.05, random_state는 수행 시마다 동일 예측 결과를 위해 설정
xgb_clf = XGBClassifier(n_estimators=500, learning_rate=0.05, random_state=156)
# 성능 평가 기준이 roc_auc이므로 eval_metric은 'auc'로 설정, 조기 중단은 100으로 설정하고 학습 수행
xgb_clf.fit(X_tr, y_tr, early_stopping_rounds=100, eval_metric='auc', eval_set=[(X_tr, y_tr), (X_val, y_val)])
xgb_roc_score = roc_auc_score(y_test, xgb_clf.predict_proba(X_test)[:, 1])
print('ROC AUC:{0:.4f}'.format(xgb_roc_score))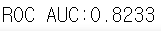
●HyperOpt를 이용해 XGBoost의 하이퍼 파라미터 튜닝
# 1. 검색 공간 설정
from hyperopt import hp
xgb_search_space = {'max_depth':hp.quniform('max_depth', 5, 15, 1), # 정수형 하이퍼 파라미터 → hp.quniform() 사용
'min_child_weight':hp.quniform('min_child_weight', 1, 6, 1), # 정수형 하이퍼 파라미터 → hp.quniform() 사용
'colsample_bytree':hp.uniform('colsample_bytree', 0.5, 0.95),
'learning_rate':hp.uniform('learning_rate', 0.01, 0.2)}- 교차검증 시 XGBoost, LightGBM의 조기 중단(early stopping)과 검증 데이터 성능 평가를 위해서 KFold를 이용해 직접 학습과 검증 데이터 세트를 추출하고 이를 교차검증 횟수만큼 학습과 성능 평가를 수행한다.(이전 글에서 말했듯이, XGBoost와 LightGBM은 교차검증 시 cross_val_score()를 사용하면 조기 중단이 지원되지 않음)
- 수행 시간을 줄이기 위해 n_estimators는 100으로 줄이고, early_stopping_rounds도 30으로 줄여서 테스트한 뒤 나중에 하이퍼 파라미터 튜닝이 완료되면 다시 증가시켜 모델 학습 및 평가 진행하기로 함(수행 시간 때문에)
# 2. 목적 함수 설정
from sklearn.model_selection import KFold # 교차검증
from sklearn.metrics import roc_auc_score
## from hyperopt import STATUS_OK
def objective_func(search_space):
xgb_clf = XGBClassifier(n_estimators=100,
max_depth=int(search_space['max_depth']), # 정수형 하이퍼 파라미터 형변환 필요:int형
min_child_weight=int(search_space['min_child_weight']), # 정수형 하이퍼 파라미터 형변환 필요:int형
colsample_bytree=search_space['colsample_bytree'],
learning_rate=search_space['learning_rate'])
# 3개 k-fold 방식으로 평가된 roc_auc 지표를 담는 list
roc_auc_list = []
# 3개 k-fold 방식 적용
kf = KFold(n_splits=3)
# X_train을 다시 학습과 검증용 데이터로 분리
for tr_index, val_index in kf.split(X_train):
# kf.split(X_train)으로 추출된 학습과 검증 index 값으로 학습과 검증 데이터 세트 분리
X_tr, y_tr = X_train.iloc[tr_index], y_train.iloc[tr_index]
X_val, y_val = X_train.iloc[val_index], y_train.iloc[val_index]
# early stopping은 30회로 설정하고 추출된 학습과 검증 데이터로 XGBClassifier 학습 수행
xgb_clf.fit(X_tr, y_tr, early_stopping_rounds=30, eval_metric='auc', eval_set=[(X_tr, y_tr), (X_val, y_val)])
# 1로 예측한 확률값 추출 후 roc auc 계산하고, 평균 roc auc 계산을 위해 list에 결과값 담음
score = roc_auc_score(y_val, xgb_clf.predict_proba(X_val)[:, 1])
roc_auc_list.append(score)
# 3개 k-fold로 계산된 roc_auc 값의 평균값을 반환하되 -1을 곱함
return -1 * np.mean(roc_auc_list) # return {'loss':-1 * np.mean(roc_auc_list), 'status':STATUS_OK}# 3. fmin()을 이용해 최적 하이퍼 파라미터 도출
from hyperopt import fmin, tpe, Trials
trials = Trials()
best = fmin(fn=objective_func,
space=xgb_search_space,
algo=tpe.suggest,
max_evals=50,
trials=trials,
# rstate=np.random.default_rng(seed=30)
)
print('best:', best)
●추출된 최적 하이퍼 파라미터를 이용하여 XGBoost의 인자로 입력하여 학습 및 평가
- n_estimators=500, early_stopping_rounds=100으로 증가시켜서 학습 및 평가 진행
# 도출된 최적 하이퍼 파라미터를 이용하여 모델 선언
xgb_clf = XGBClassifier(n_estimators=500,
learning_rate=round(best['learning_rate'], 5),
max_depth=int(best['max_depth']),
min_child_weight=int(best['min_child_weight']),
colsample_bytree=round(best['colsample_bytree'], 5)
)
# 모델 학습
xgb_clf.fit(X_tr, y_tr, early_stopping_rounds=100,
eval_metric='auc', eval_set=[(X_tr, y_tr), (X_val, y_val)])
# 예측 및 모델 평가
xgb_roc_score = roc_auc_score(y_test, xgb_clf.predict_proba(X_test)[:, 1])
print('ROC AUC:{0:.4f}'.format(xgb_roc_score))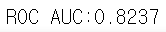
●피처 중요도
from xgboost import plot_importance
import matplotlib.pyplot as plt
%matplotlib inline
fig, ax = plt.subplots(figsize=(10,8))
plot_importance(xgb_clf, ax=ax, max_num_features=20, height=0.4) # 상위 20개 피처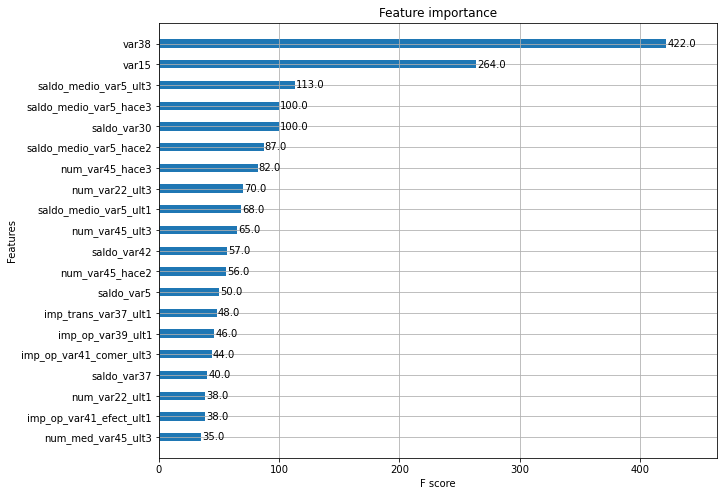
4. LightGBM Model
●대략적인 모델의 성능을 확인해보자
from lightgbm import LGBMClassifier
lgbm_clf = LGBMClassifier(n_estimators=500)
eval_set = [(X_tr, y_tr), (X_val, y_val)]
lgbm_clf.fit(X_tr, y_tr, early_stopping_rounds=100, eval_metric='auc', eval_set=eval_set)
lgbm_roc_score = roc_auc_score(y_test, lgbm_clf.predict_proba(X_test)[:, 1])
print('ROC AUC:{0:.4f}'.format(lgbm_roc_score))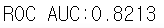
●HyperOpt를 이용해 LightGBM의 하이퍼 파라미터 튜닝
# 1. 검색 공간 설정
lgbm_search_space = {'num_leaves':hp.quniform('num_leaves', 32, 64, 1),
'max_depth':hp.quniform('max_depth', 100, 160, 1),
'min_child_samples':hp.quniform('min_child_samples', 60, 100, 1),
'subsample':hp.uniform('subsample', 0.7, 1),
'learning_rate':hp.uniform('learning_rate', 0.01, 0.2)
}# 2. 목적 함수 설정
def objective_func(search_space):
lgbm_clf = LGBMClassifier(n_estimators=100,
num_leaves=int(search_space['num_leaves']),
max_depth=int(search_space['max_depth']),
min_child_samples=int(search_space['min_child_samples']),
subsample=search_space['subsample'],
learning_rate=search_space['learning_rate'])
roc_auc_list=[]
kf = KFold(n_splits=3)
for tr_index, val_index in kf.split(X_train):
X_tr, y_tr = X_train.iloc[tr_index], y_train.iloc[tr_index]
X_val, y_val = X_train.iloc[val_index], y_train.iloc[val_index]
lgbm_clf.fit(X_tr, y_tr, early_stopping_rounds=30, eval_metric='auc',
eval_set=[(X_tr, y_tr), (X_val, y_val)])
score = roc_auc_score(y_val, lgbm_clf.predict_proba(X_val)[:, 1])
roc_auc_list.append(score)
return -1 * np.mean(roc_auc_list)# 3. fmin()을 이용해 최적 하이퍼 파라미터 도출
from hyperopt import fmin, tpe, Trials
trials = Trials()
best = fmin(fn=objective_func,
space=lgbm_search_space,
algo=tpe.suggest,
max_evals=50,
trials=trials,
# rstate=np.random.default_rng(seed=30)
)
print('best:', best)
●추출된 최적 하이퍼 파라미터를 이용하여 LightGBM의 인자로 입력하여 학습 및 평가
lgbm_clf = LGBMClassifier(n_estimators=500,
num_leaves=int(best['num_leaves']),
max_depth=int(best['max_depth']),
min_child_samples=int(best['min_child_samples']),
subsample=round(best['subsample'], 5),
learning_rate=round(best['learning_rate'], 5)
)
lgbm_clf.fit(X_tr, y_tr, early_stopping_rounds=100, eval_metric='auc',
eval_set=[(X_tr, y_tr), (X_val, y_val)])
lgbm_roc_score = roc_auc_score(y_test, lgbm_clf.predict_proba(X_test)[:, 1])
print('ROC AUC:{0:.4f}'.format(lgbm_roc_score))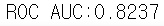
'파이썬 머신러닝 완벽가이드 > [4장] 분류' 카테고리의 다른 글
| 캐글 신용카드 사기 검출 (0) | 2023.02.25 |
|---|---|
| 캐글 신용카드 사기 검출(log 변환, 이상치 제거, SMOTE 오버샘플링 기초지식) (0) | 2023.02.24 |
| 베이지안 최적화 기반의 HyperOpt를 이용한 하이퍼 파라미터 튜닝(2) (0) | 2023.02.22 |
| 베이지안 최적화 기반의 HyperOpt를 이용한 하이퍼 파라미터 튜닝(1) (0) | 2023.02.20 |
| LightGBM (0) | 2023.02.19 |