CREATE TABLE AS SELECT
- city 테이블과 똑같은 city2 테이블 생성
CREATE TABLE city2
AS SELECT *
FROM city;
CREATE DATABASE
- 새로운 데이터베이스를 생성
- USE문으로 새 데이터베이스를 사용
- Navigator, Schemas에서 마우스 우클릭 'Refresh All' → 만든 데이터베이스가 보임
CREATE DATABASE suan;
USE suan;
CREATE TABLE
- GUI로 만들수 있음
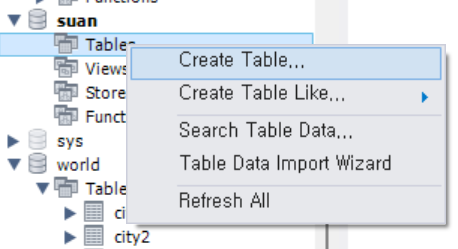
- 코드로 만들기
CREATE TABLE test2 (
id INT NOT NULL PRIMARY KEY,
col1 INT NULL,
col2 FLOAT NULL,
col3 VARCHAR(45) NULL
);
ALTER TABLE
- ALTER TABLE문과 함께 ADD문을 사용하면, 테이블에 컬럼을 추가할 수 있음
ALTER TABLE test2
ADD col4 INT NULL;
- ALTER TABLE문과 함게 MODIFY문을 사용하면, 테이블의 컬럼 타입을 변경할 수 있음
ALTER TABLE test2
MODIFY col4 VARCHAR(20) NULL;
- ALTER TABLE문과 함께 DROP문을 사용하면, 테이블에 컬럼을 제거할 수 있음
ALTER TABLE test2
DROP col4;
인덱스
- 테이블에서 원하는 데이터를 빠르게 찾기 위해 사용
- 일반적으로 데이터를 검색할 때 순서대로 테이블 전체를 검색하므로 데이터가 많으면 많을수록 탐색하는 시간이 늘어남.하지만 인덱스를 사용할 경우 검색과 질의를 할 때 테이블 전체를 읽지 않기 때문에 빠름
- 설정된 컬럼 값을 포함한 데이터의 삽입, 삭제, 수정 작업이 원본 테이블에서 이루어질 경우, 인덱스도 함께 수정되어야 함. 그래서 인덱스가 있는 테이블은 처리 속도가 느려질 수 있으므로 수정보다는 검색이 자주 사용되는 테이블에서 사용하는 것이 좋음
CREATE INDEX
CREATE INDEX문을 사용하여 인덱스를 생성
CREATE INDEX Col1idx
ON test (col1);
SHOW INDEX
인덱스 정보 보기
SHOW INDEX FROM test;
CREATE UNIQUE INDEX
중복 값을 허용하지 않는 인덱스를 생성
CREATE UNIQUE INDEX Col2idx
ON test (col2);
FULLTEXT INDEX
일반적인 인덱스와는 달리 매우 빠르게 테이블의 모든 텍스트 컬럼을 검색
ALTER TABLE test
ADD FULLTEXT Col3idx(col3);
INDEX 삭제
- ALTER: ALTER 문을 사용하여 테이블에 추가된 인덱스 삭제
ALTER TABLE test
DROP INDEX Col3idx;
- DROP INDEX: DROP 문을 사용하여 해당 테이블에서 명시된 인덱스를 삭제
DROP INDEX Col2idx ON test;
- 둘 중 하나 사용
VIEW
- 뷰는 데이터베이스에 존재하는 일종의 가상 테이블
- 실제 테이블처럼 행과 열을 가지고 있지만, 실제로 데이터를 저장하진 않음
- MySQL에서 뷰는 다른 테이블이나 다른 뷰에 저장되어 있는 데이터를 보여주는 역할만 수행
- 뷰를 사용하면 여러 테이블이나 뷰를 하나의 테이블처럼 볼 수 있음
- 장점
1) 특정 사용자에게 테이블 전체가 아닌 필요한 컬럼만 보여줄 수 있음
2) 복잡한 쿼리를 단순화해서 사용
3) 쿼리 재사용 가능
- 단점
1) 한 번 정의된 뷰는 변경할 수 없음
2) 삽입, 삭제, 갱신 작업에 많은 제한 사항을 가짐
3) 자신만의 인덱스를 가질 수 없음
CREATE VIEW
CREATER VIEW 문을 사용하여 뷰 생성
CREATE VIEW testView AS
SELECT Col1, Col2
FROM test;
SELECT * FROM testView;
ALTER VIEW
ALTER 문을 사용하여 뷰를 수정
ALTER VIEW testView AS
SELECT Col1, Col2, Col3
FROM test;
SELECT * FROM testView;
DROP VIEW
DROP 문을 사용하여 생성된 뷰를 삭제
DROP VIEW testView;
INSERT
- INSERT INTO 문을 사용하여 테이블에 새로운 레코드를 추가할 수 있음
- 문법
1. INSERT INTO 테이블이름(필드이름1, 필드이름2, 필드이름3, ...)
VALUES (데이터값1, 데이터값2, 데이터값3, ...)
2. INSERT INTO 테이블이름
VALUES (데이터값1, 데이터값2, 데이터값3, ...)
- 테이블이름 다음에 나오는 열 생략 가능
- 생략할 경우에 VALUES 다음에 나오는 값들의 순서 및 개수가 테이블이 정의된 열 순서 및 개수와 동일해야 함
INSERT INTO test
VALUES(1, 123, 1.1, "Test");
3. Workbench
Workbench에서 바로 입력 후 Apply

INSERT INTO SELECT
- test 테이블에 있는 내용을 test2 테이블에 삽입(테이블의 데이터를 우리가 복사하고자 하는 대상 테이블로 복사하는 기능을 가진 구문)
INSERT INTO test2 SELECT * FROM test;
UPDATE
- 기존에 입력되어 있는 값을 변경하는 구문
- WHERE절 생략 가능하나 테이블의 전체 행의 내용 변경
UPDATE test
SET col1 = 1, col2 = 1.0, col3 = 'test'
WHERE id = 1;
DELETE
- 행 단위로 데이터 삭제하는 구문
- DELETE FROM 테이블이름 WHERE 조건;
- WHERE절을 안쓰면 전체 다 날라
- 데이터는 지워지지만 테이블 용량은 줄어들지 않음
- 원하는 데이터만 지울 수 있음
- 삭제 후 잘못 삭제한 것을 되돌릴 수 있음
DELETE FROM test
WHERE id = 1;
TRUNCATE
- 용량이 줄어들고, 인덱스 등도 모두 삭제
- 테이블은 삭제하지는 않고, 데이터만 삭제(테이블의 데이터를 전부 삭제하고 사용하고 있던 공간을 반납)
- 삭제 후 절대 되돌릴 수 없음
TRUNCATE TABLE test;
DROP TABLE
- 테이블 자체를 삭제
- 삭제 후 절대 되돌릴 수 없음
DROP TABLE test;
DROP DATABASE
- DROP DATABASE 문은 해당 데이터베이스를 삭제
DROP DATABASE suan;
Reference)
유튜브 '이수안컴퓨터연구소 MySQL 데이터베이스 한번에 끝내기'
유튜브 '코딩애플 index'
'SQL' 카테고리의 다른 글
| MySQL(2) (0) | 2023.05.19 |
|---|---|
| MySQL(1) (0) | 2023.05.18 |
| DDL, DML, DCL (0) | 2023.05.18 |