특징 간 상관성이 높을 때 문제점
●회귀 모델, 신경망, SVM과 같이 'wx+b' 형태의 선형식이 모델에 포함되는 경우, 특징 간 상관성이 높으면 강건한 파라미터 추정이 어렵다. 즉, 추정할 때마다 결과가 달라질 수 있다.(모델로 predict(예측)하는 값이 달라질 수 있다.)
아래 예시를 보자.

x1과 x2를 이용하여 y를 예측하는 회귀 모델에서 y=2x1이고, x2=x1이라면 결론적으로 w1과 w2가 무수히 많은 해를 갖는 다는 문제가 있다. 그래서 강건한 파라미터 추정이 어려워서 추정할 때마다 결과가 달라질 수 있다.
회귀 모델의 경우 잔차제곱합을 최소화를 하는 과정에서 미분을 해야하는데 미분을 할 때 결과식에 역행렬이 포함이 된다. 특징 간 상관성이 높으면 역행렬이 존재하지 않을 수 있어서 해를 구하는게 불가능 할 수도 있다.
●트리 계열의 모델은 사실 특징 간 상관성이 높다고 해서 모델 예측 성능에 영향을 받지 않지만, 상관성이 높은 변수 중 소수만 모델에 포함되기 때문에 설명력이 크게 영향을 받을 수 있다.
극단적인 예를 들어, x1과 x2처럼 아에 같은 특징이 있다면 x1을 기준으로 분리를 하던 x2를 기준으로 분리를 하던 똑같기 때문에 둘 중 하나를 임의로 선택을 할 것이다. 그러면 x2로 분리를 했으면 x1은 분리할 필요가 없고, x1으로 분리를 했으면 x2는 분리할 필요가 없다. 모델상에서 x1과 x2중 둘 중 하나만 등장하기 때문에 남은 다른 하나가 어떤 영향을 끼치는지 모델상에서 반영되지 않기 때문에 설명력 문제가 발생할 수 있다.(x2가 등장 했다면 x1은 모델에 어떤 영향을 끼치는지 반영이 안되기 때문에 설명력 문제가 발생할 수 있다.)
해결 방법 1. VIF 활용
주로 회귀 모델에서 다중공선성 문제를 해결할 때 사용하는 지표이다.
Variance Inflation factors(VIF, 분산 팽창 계수)는 한 특징을 라벨로 간주하고, 해당 라벨을 예측하는데 다른 특징을 사용한 회귀 모델이 높은 R2(R 스퀘어(결정계수, 설명력): 회귀 모델에서 적합성 지표로 0~1 사이의 범위를 가지고 1로 갈수록 좋은 모델이라고 판단할 수 있는 지표)을 보이는 경우 해당 특징이 다른 특징과 상관성이 있다고 판단한다.
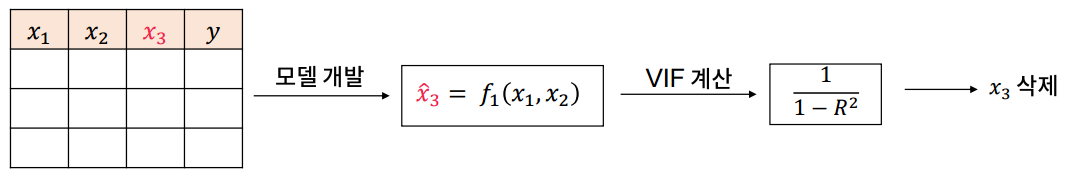
VIF가 높은 순서대로 특징을 제거하거나, VIF가 10 이상인 경우 그 변수는 다른 변수와 상관성이 매우 높다고 판단해서 일반적으로 삭제한다.
해결 방법 2. 주성분 분석(PCA)
주성분 분석을 이용하여 특징이 서로 직교하도록 만들어 특징 간 상관성을 줄이는 방법이다.
아래의 그림을 예를 들어보면, 기존에 차원이 x1과 x2로 구성되어 있고 데이터들이 있다. 이 데이터들을 원래 특징(x1, x2)이 아니라 새로운 차원으로 데이터를 투영시키는 방법이다. z1이라는 축과 z2라는 축을 찾아서 이 두 개의 축을 바탕으로 데이터를 투영시킨다. (z1과 z2는 우연히 찾은 것이 아니고 이 데이터의 방향을 보니 z1 방향과 z2 방향으로 배치되어 있기 때문이다.) 그리고 이 z1과 z2를 주성분이라고 부르고 이 그림에서는 수학적으로 z1이 z2보다 이 데이터의 분산을 더 잘 설명한다.
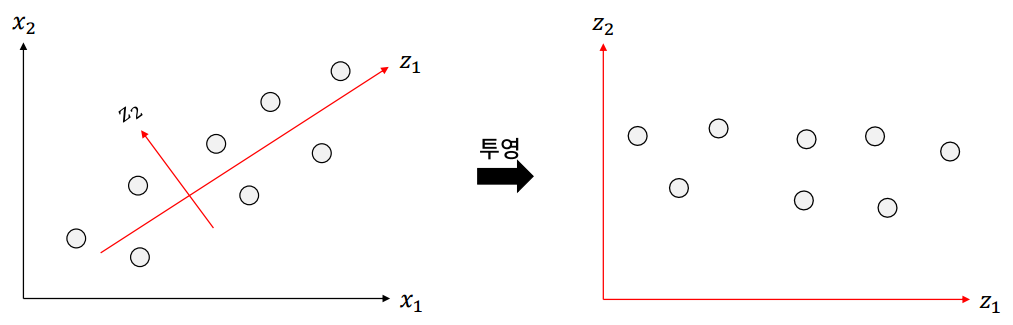
주성분 분석으로 데이터를 투영시키고 나면 데이터의 차원은 같지만 데이터의 분산을 설명하는 정도를 측정해서 정도가 높은 차원만 골라서 차원을 줄인다. 그리고 주성분으로 축을 회전시켜서 특징이 서로 직교하도록 만들어(데이터를 더 잘 설명 하는 축 방향으로) 특징 간 상관성을 줄인다.
→n차원의 데이터는 총 n개의 주성분이 존재하지만, 주성분을 다쓰는 것은 의미가 없기 때문에 차원 축소 등을 위해 분산의 대부분을 설명하는 m < n 주성분만 사용하는 것이 일반적이다.(n보다 작은 m개의 주성분만 사용)
- 관련 문법: sklearn.decomposition.PCA
주성분 분석을 수행하는 인스턴스를 생성하는 함수이다.
-주요 입력
▷n_components: 사용할 주성분 개수를 나타내며, 이 값은 기존 차원 수(변수 수)보다 작아야 함
-주요 attribute
▷.explained_variance_ratio: 각 주성분이 원 데이터의 분산을 설명하는 정도, 보통 1등부터 n등까지 점수가 있을 때 누적합이 보통 90%(0.9)가 넘는 정도에서 끊는다.
## 코드 실습 ##
import os
os.chdir(r"C:\Users\82102\Desktop\데이터전처리\머신러닝 모델의 성능 향상을 위한 전처리\5. 머신러닝 모델의 성능 향상을 위한 전처리\데이터")
import pandas as pddf = pd.read_csv("abalone.csv")
df.head()
# 특징과 라벨 분리
X = df.drop('Age', axis=1)
Y = df['Age']# 학습 데이터와 평가 데이터 분리
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X, Y)# 특징 간 상관관계를 보기위해 상관행렬 출력
x_train.corr() # 특징 간 상관관계가 존재하며 높음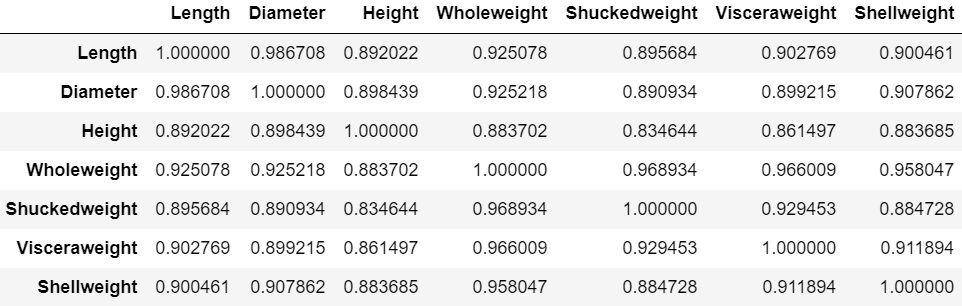
- VIF 기준 특징 선택
# VIF 계산
from sklearn.linear_model import LinearRegression as LR
VIF_dict = dict()
# 하나의 특징을 라벨로 간주하고, 다른 특징들로 해당 라벨을 맞추기 위한 선형회귀모델을 학습해서 그 모델의 R스퀘어를 측정하는 방식임
for col in x_train.columns:
model = LR().fit(x_train.drop([col], axis=1), x_train[col])
r2 = model.score(x_train.drop([col], axis=1), x_train[col]) # LinearRegression의 score가 r2 점수임
VIF = 1 / (1 - r2)
VIF_dict[col] = VIFVIF_dict
# Height를 제외하곤 VIF가 모두 10보다 큼
# 이러한 상황에서는 사실 PCA를 사용하는 것이 바람직
# 모델 성능 비교를 위해 VIF 점수가 30점 미만인 특징만 사용하기로 결정
from sklearn.neural_network import MLPRegressor as MLP
from sklearn.metrics import mean_absolute_error as MAE
# 전체 특징을 모두 사용하였을 때
model = MLP(random_state = 2313, max_iter = 500)
model.fit(x_train, y_train)
pred_y = model.predict(x_test)
score = MAE(y_test, pred_y)
print(score)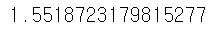
# VIF 점수가 30점 미만인 특징만 사용하였을 때
# VIF 점수가 30점 미만인 특징만 추출
selected_features = [key for key, val in VIF_dict.items() if val < 30]
selected_features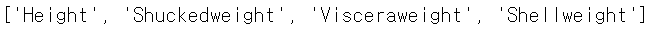
model = MLP(random_state = 2313, max_iter = 500)
model.fit(x_train[selected_features], y_train)
pred_y = model.predict(x_test[selected_features])
score = MAE(y_test, pred_y)
print(score)
VIF 점수가 30점 미만인 특징만 사용했을 때 성능이 더 좋아졌음을 확인한다.
- PCA 사용
from sklearn.decomposition import PCA
# 인스턴스화 및 학습
PCA_model = PCA(n_components = 3).fit(x_train)
# transform
z_train = PCA_model.transform(x_train)
z_test = PCA_model.transform(x_test)
print(z_train.shape) # 주성분 3개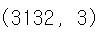
model = MLP(random_state = 2313, max_iter = 500)
model.fit(z_train, y_train)
pred_y = model.predict(z_test)
score = MAE(y_test, pred_y)
print(score)
PCA를 사용하니 모델의 성능이 더 좋아진걸 확인한다.
'데이터 전처리 > 머신러닝 모델의 성능 향상을 위한 전처리' 카테고리의 다른 글
| 클래스 불균형 문제 (0) | 2022.12.27 |
|---|---|
| 변수 분포 문제-특징간 스케일 차이 해결하기(스케일링) (0) | 2022.12.26 |
| 변수 분포 문제-변수 치우침 제거 (0) | 2022.12.26 |
| 변수 분포 문제-이상치 제거 (0) | 2022.12.22 |
| 변수 분포 문제-특징과 라벨 간 약한 관계 또는 비선형 관계일때 (0) | 2022.12.22 |