클래스 불균형 문제란?
클래스 변수가 하나의 값에 치우친 데이터로 학습한 분류 모델이 치우친 클래스에 대해 편향되는 문제로, 이러한 모델은 대부분 샘플을 치우친 클래스 값으로만 분류하게 된다(예시: 암환자 판별 문제)
예를들어, 암환자와 정상인이 있을 때 암환자 수가 훨씬 적을텐데 이러한 데이터를 가지고 모델을 만들게 되면 이 모델은 대부분을 정상인이라고 분류를 할 것이다. 그렇게되면 우리가 더 판별하고 싶어하는 암환자를 제대로 판별하지 못하는 상황이 발생할 수 있다.
그리고 클래스 불균형 문제는 분류에서만 발생하는 문제이다.
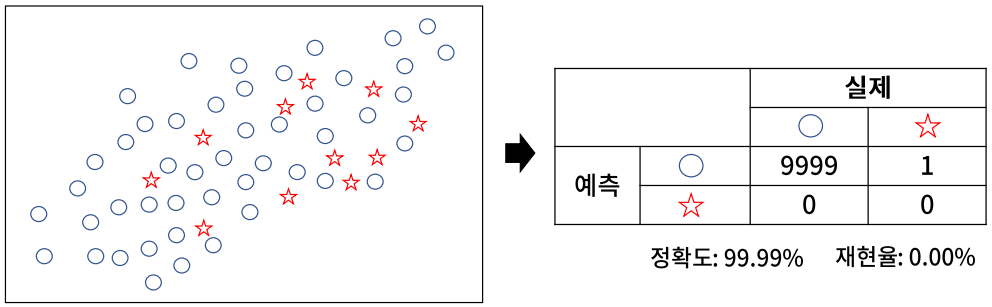
위의 그림을 통해 알 수 있듯이, 클래스 불균형 문제가 있는 모델은 정확도가 높고, 재현율이 매우 낮은 경향이 있다.
- 용어
# FP, FN, TP, TN은 머리속으로 혼동행렬을 그려본다!!

-다수 클래스: 대부분 샘플이 속한 클래스(예: 정상인)
-소수 클래스: 대부분 샘플이 속하지 않은 클래스(예: 암환자)
-위양성 비용(False positive; FP): 부정 클래스 샘플을 긍정 클래스 샘플로 분류해서 발생하는 비용
-위음성 비용(False negative; FN): 긍정 클래스 샘플을 부정 클래스 샘플로 분류해서 발생하는 비용
# 위양성이란 실제로 병이 없는데 검사 결과에서는 마치 병이 있는 것처럼 나오는 경우 / 위음성이란 실제로 병이 있는데 검사 결과에서는 마치 병이 없는 것처럼 나오는 경우
# '위'는 위선을 뜻하는 즉, 거짓이라는 뜻이다.
# 긍정 클래스는 우리가 예측 하고 싶은 것이고 부정 클래스는 그 반대
→보통은 위음성 비용이 위양성 비용보다 훨씬 크다.(예: 위양성 비용(정상인→암환자) vs 위음성 비용(암환자→정상인))
예를들어, 정상인을 암환자라고 분류를 한다면 정상인은 자신이 암환자라고 착각을 하고 재검사를 받을 것이다. 물론 거기서 발생하는 돈과 시간의 비용이 발생 할 것이다. 반대로 암환자를 정상인이라고 분류를 한다면 암환자는 자신이 정상이라고 착각해서 추가적인 검사나 수술을 하지 않고 퇴원을 할 것이다. 그런데 실제로 암환자였기 때문에 암이 더 악화되면서 죽음을 맞이할 것이다.
즉, 위양성 비용은 돈과 시간, 위음성 비용은 생명이라는 비용이 들고 당연히 생명이라는 비용이 더 큰 비용이라는 것을 알 수 있다.
이와 동일하게 양품과 불양품 예시도 마찬가지이다.
- 발생 원인
1. 근본적인 원인은 클래스 비율이 맞지 않기 때문이다.
2. 대부분 분류 모형의 학습 목적식은 정확도를 최대화하는 것이다. 정확도를 최대화하다 보니 굳이 소수클래스를 잘 분류하기 위한 노력을 할 필요가 없다. 그래서 대부분 샘플을 다수 클래스라고 분류하도록 학습된다.

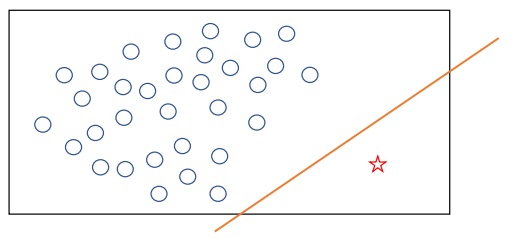
위 두 그림 모두 동그라미 데이터가 8개, 별 데이터가 2개이다. 별 데이터가 긍정 클래스라고 가정한다.
어느 모델이 더 좋냐라고 했을 때 대부분의 분류 모형은 왼쪽을 더 좋다고 평가한다. 즉, 학습 목적식에 의해서 정확도만 최대화 한다는 소리이다. 그래서 기본적으로 분류 모형의 학습 목적식에 의해서 정확도만 높아지는 현상이 발생하는것이다.
클래스 불균형 탐색 방법 1. 클래스 불균형 비율
클래스 불균형 비율이 일반적으로 9 이상이면 편향된 모델이 학습될 가능성이 있다.

다만, 클래스 불균형 비율이 높다고 해서 반드시 편향된 모델을 학습하는 것은 아니다.
→클래스 불균형 문제라는 것은 클래스 자체가 불균형한게 문제가 아니고, 불균형하기 때문에 편향된 모델이 만들어지는 것이 문제다. 그래서 클래스 불균형 비율은 참고용으로 보고 실제로 모델이 편향이 되는지 아닌지를 판단하기 위한 방법이 필요하다. 그 방법이 k-최근접 이웃을 활용하는 방법이다.
클래스 불균형 탐색 방법 2. k-최근접 이웃을 활용하는 방법
k-최근접 이웃은 이웃의 클래스 정보를 바탕으로 분류를 하기에 클래스 불균형에 매우 민감하므로, 클래스 불균형 문제를 진단하는데 적절하다.(k-최근접 이웃은 이웃의 클래스 정보를 바탕으로 분류를 하기에 클래스 불균형에 매우 민감해서 클래스 불균형 문제가 있는 경우 사용하면 안되는 모델이지만, 역으로 그걸 활용해서 클래스 불균형 문제에 테스트 하는데 쓸 수 있는 아이디어)

k값이 크면 클수록(이웃이 많으면 많을수록) 더욱 민감하므로, 보통 5~11 정도의 k를 설정하여 문제를 진단한다.(11로 많이 설정)
[참고]정상인:1000명, 암환자:10명 가정
k값이 커질수록, 즉, 이웃이 많을수록 민감하다는 말은 클래스 불균형으로 인해 정상인이 엄청 많을텐데 거기에 k(이웃)의 수를 늘리면 주변 이웃이 정상인들이 있을 확률이 더 높아져 정상인으로 분류를 할 확률이 더 높아지기 때문에 k값이 커질수록 더욱 민감하다는 소리이다.
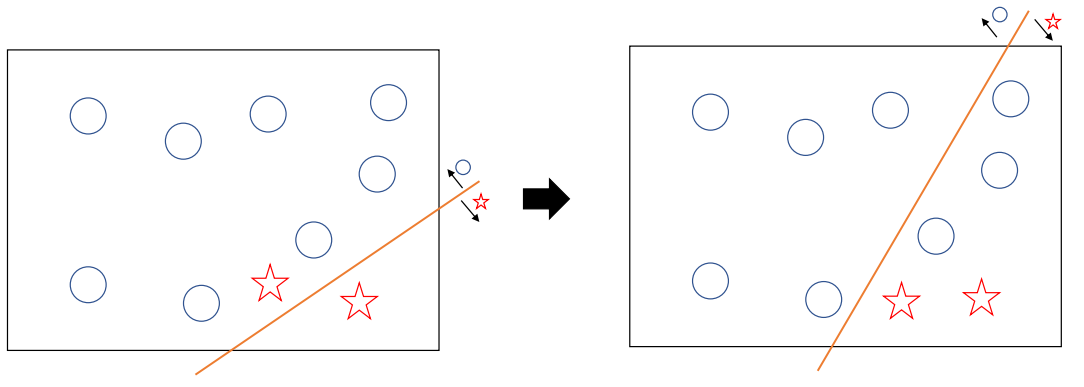
클래스 불균형 문제 해결의 기본 아이디어
클래스 불균형 문제 해결의 기본 아이디어는 소수 클래스에 대한 결정 공간을 넓히는 것이다.
'데이터 전처리 > 머신러닝 모델의 성능 향상을 위한 전처리' 카테고리의 다른 글
| 클래스 불균형 문제 해결방법(2) 비용 민감 모델 (0) | 2022.12.28 |
|---|---|
| 클래스 불균형 문제 해결방법(1) 재샘플링 (0) | 2022.12.27 |
| 변수 분포 문제-특징간 스케일 차이 해결하기(스케일링) (0) | 2022.12.26 |
| 변수 분포 문제-변수 치우침 제거 (0) | 2022.12.26 |
| 변수 분포 문제-특징 간 상관성 제거(특징 선택) (0) | 2022.12.25 |