특징 간 스케일 차이 문제
특징 간 스케일이 달라서 발생하는 문제로, 스케일이 큰 변수에 의해 혹은 스케일이 작은 변수에 의해 모델이 크게 영향을 받는 문제를 의미한다.
▷스케일이 큰 변수에 영향을 받는 모델: k-최근접 이웃
k-최근접 이웃은 거리 기반 모델이기 때문에 거리는 스케일이 큰 변수에 영향을 많이 받는다.
▷스케일이 작은 변수에 영향을 받는 모델: 회귀모델, 서포트 벡터 머신, 신경망('wx+b' 꼴의 함수가 들어간 모델)
▷스케일에 영향을 받지 않는 모델: 나이브베이즈, 의사결정나무(이진 분류에 한함)
특징 간 스케일 차이 해결 방법
스케일링을 사용하여 변수 간 스케일 차이를 줄이는 방법으로 해결한다.

Standar Scaling은 범위가 이론적으로 [-∞ ~ +∞]이지만 보통 [-3 ~ +3]로 왔다갔다 하는게 일반적이다.
Min-max Scaling은 범위가 항상 [0 ~ 1]에서 왔다갔다 한다.
●모델에 따른 스케일러 선택
▷Standard Scaler: 특징의 정규 분포를 가정하는 모델(예: 회귀모델, 로지스틱회귀모델)
▷Min-Max Scaler: 특정 분포를 가정하지 않는 모델(예: 신경망, k-최근접 이웃)
→개인적으로 Standard Scaler를 사용하더라도 스케일이 완벽하게 변수간에 맞지 않기 때문에 변수간에 스케일을 완벽하게 갖출수 있는 Min-Max Scaler가 좀 더 바람직하다고 생각한다.
●관련 문법: sklearn.preprocessing.MinMaxScaler & StandardScaler
Min max scaling과 standard scaling을 수행하는 인스턴스를 생성하는 함수이다.
- 주요 메서드
▷fit: 변수별 통계량을 계산하여 저장(min max scaler: 최대값 및 최소값, standard scaler: 평균 및 표준편차)
▷transform: 변수별 통계량을 바탕으로 스케일링 수행
▷inverse_transform: 스케일링된 값을 다시 원래 값으로 변환
## 코드 실습 ##
import os
os.chdir(r"C:\Users\82102\Desktop\데이터전처리\머신러닝 모델의 성능 향상을 위한 전처리\5. 머신러닝 모델의 성능 향상을 위한 전처리\데이터")
import pandas as pddf = pd.read_csv("baseball.csv")
df.head()
# 특징과 라벨 분리
X = df.drop('Salary', axis=1)
Y = df['Salary']# 학습 데이터와 평가 데이터 분리
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X, Y)# 특징 간 스케일 차이 확인
x_train.max() - x_train.min() # 특징 간 스케일 차이가 큼
# 스케일이 작은 특징은 KNN 모델에 영향을 거의 주지 못할 것이라 예상
# 'Free_agency_eligibility', 'Free_agent', 'Arbitration_eligibility', 'Arbitration' 변수들은 1인걸로 보아 이진형 변수
# 스케일링 전에 성능 확인
from sklearn.neighbors import KNeighborsRegressor as KNN
from sklearn.metrics import mean_absolute_error as MAE
model = KNN().fit(x_train, y_train)
pred_y = model.predict(x_test)
score = MAE(y_test, pred_y)
print(score)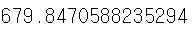
# 스케일링 수행
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler().fit(x_train)
s_x_train = scaler.transform(x_train)
s_x_test = scaler.transform(x_test)# 스케일링 후에 성능 확인
model = KNN().fit(s_x_train, y_train)
pred_y = model.predict(s_x_test)
score = MAE(y_test, pred_y)
print(score)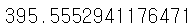
스케일링을 했을 때 성능이 좋아진 것을 볼 수 있다.
부가설명(참고)
기존 스케일은 다음과 같다. 위에서 KNN의 모델의 default가 유클리디안이기 때문에 Runs ,Hits, Strike-Outs 같은 스케일이 큰 변수들이 모델에 거의 영향을 미쳤을 것이다. 예를들어, Batting_average는 스케일 차이가 아무리 나봤자 0.346인데 Runs같은 경우 스케일 차이가 많이 나면 100도 그냥 넘기 때문에 스케일이 0.346 차이나는 Batting_average와 스케일이 133 차이나는 Runs의 간극에 의해서 Batting_average는 무시가 됐을 것이다. 즉, Batting_average 같은 좋은 특징이 있음에도 불구하고 이거는 스케일이 작아서 모델에 영향을 거의 주지 않았을 것이다.
이번 실습에서는 스케일링을 해서 성능이 좋아졌지만, 스케일링을 해서 성능이 떨어지는 경우도 당연히 존재한다.
예를들어, Batting_average 변수가 라벨과 아무런 관련이 없는 쓸모 없는 변수라고 가정한다면 이 변수는 스케일이 작아서 무시되고 있으니 오히려 잘된것이다. 그런데 스케일링을 하다보니 쓸모 없는 변수가 영향력이 커져 성능이 저하될수 있다.
(아주 쓸모가 없는 변수인데 스케일도 작아서 애초에 모델에 영향을 안주고 있었는데 스케일링을 해서 스케일을 맞출경우 모델에 안좋은 영향이 커질 수 있기 때문이다.)
그래서 스케일링을 했을때 성능이 안좋아졌다면 그 근거가 뭔지 찾아야 한다. (ex. 어떤 변수가 스케일이 작아서 애초에 모델에 영향을 안 주고 있고, 스케일링 하지 않은 모델 성능과 스케일링 한 모델 성능을 비교해보니 스케일링 했을 때 성능이 안좋아 졌다->그러면 어떤 변수는 스케일링 문제가 아니고 변수 자체가 의미가 없다고 판단하고 drop하는 결론을 이끌 수 있어야 한다.)
즉, '어떤 상황에서 이렇게 하면 무조건 좋아진다'라고 하는 전처리 기법, 탐색 기법, 모델링 기법은 존재 할 수 없다.
'데이터 전처리 > 머신러닝 모델의 성능 향상을 위한 전처리' 카테고리의 다른 글
| 클래스 불균형 문제 해결방법(1) 재샘플링 (0) | 2022.12.27 |
|---|---|
| 클래스 불균형 문제 (0) | 2022.12.27 |
| 변수 분포 문제-변수 치우침 제거 (0) | 2022.12.26 |
| 변수 분포 문제-특징 간 상관성 제거(특징 선택) (0) | 2022.12.25 |
| 변수 분포 문제-이상치 제거 (0) | 2022.12.22 |