변수 분포 문제란?
일반화된 모델을 학습하는데 어려움이 있는 분포를 가지는 변수가 있어서, 일반화된 모델을 학습하지 못하는 문제이다.
변수 분포 문제를 해결하지 않아도 모델 학습 자체는 가능하지만 좋은 성능을 기대하기 어렵다.
변수 분포 문제의 대표적인 다섯가지를 알아볼 것이다.
1) 특징과 라벨 간 약한 관계 또는 비선형 관계일 때
2) 이상치를 포함하는 데이터가 있을 때
3) 특징 간 상관성이 높아서 발생하는 문제
4) 변수가 정규분포를 따르지 않고 일반분포(알수없는 분포)를 따르는 경우(변수 치우침 제거)
5) 변수 간 스케일 차이가 커서 발생하는 문제(스케일링)
특징과 라벨 간 약한 관계 또는 비선형 관계일 때
특징과 라벨 간 관계가 없거나 매우 약하다면, 어떠한 전처리 및 모델링을 하더라도 예측력이 높은 모델을 만들 수 없다.
가장 이상적인 해결 방안은 라벨에 유의미한 특징의 데이터를 구하는 것이다.
그 다음 이상적인 해결 방안은 각 특징에 대해, 특징과 라벨 간 관계를 나타내는 그래프를 통해 적절한 특징 변환을 수행해야 한다.(특징과 라벨 간 비선형 관계가 존재한다면, 적절한 전처리를 통해 모델 성능을 크게 향상시킬 수 있음)
예를들어, 대다수의 머신러닝 모델은 선형식(wx+b)을 포함하는데(선형회귀모델, 로지스틱회귀모델, svm, mlp) 선형회귀 모델에서 데이터랑 초록색 모델은 거의 일치하는 것을 볼수있으나 파란색 모델은 실제 데이터의 분포를 거의 반영하지 못한다. 모델1은 X를 그대로 사용하고 모델2는 X^2을 사용한 것 밖에 차이가 없지만 단순한 변환임에도 불구하고 데이터의 X와 Y간 비선형 관계가 있는 경우(특징과 라벨 간 비선형 관계가 있는 경우)에는 특징 변환을 해줬을 때 엄청난 퍼포먼스를 얻을 수 있다.
→MAE나 RMSE는 구하지 않아도 당연히 초록색 모델의 성능이 훨씬 우수할 것으로 예상한다.
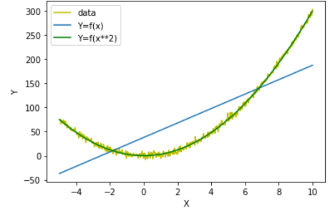
하지만 특징 개수가 많고, 다른 특징에 의한 영향도 존재하는 등 그래프를 통해 적절한 변환 방법을 선택하는 것은 쉽지 않다.→현실적으로 어려움
결론: 다양한 변환 방법(x제곱도 만들어보고, 로그x도 만들어보고, exp(x)도 만들어보고, 제곱근도 만들어보고, 아니면 두 컬럼을 더해보고, 빼보고 하는 등의 특징들을 만들어보고)을 시도하여 특징을 생성한 뒤 모델의 성능이 좋아지는 것을 고르면되고, 그 가운데 특징이 너무 많이 생기니 특징 선택까지 포함시키면 문제를 해결할수 있다.
즉, 다양한 변환 방법을 사용하여 특징을 생성한 뒤 특징 선택을 수행해야 한다.(특징 선택은 추후 포스팅에서 공부할 예정이다.)
## 코드 실습 ##
이번 실습은 기존 특징들을 가지고 다양한 변환 방법을 사용하여 새로운 특징들을 임의로 생성해서 모델링을 해보고, 기존 특징들만 가지고 모델링을 한 결과와 비교를 위한 실습이다.
import os
os.chdir(r"C:\Users\82102\Desktop\데이터전처리\머신러닝 모델의 성능 향상을 위한 전처리\5. 머신러닝 모델의 성능 향상을 위한 전처리\데이터")
import pandas as pd
import numpy as npdf = pd.read_csv("Combined_Cycle_Power_Plant.csv")
df.head()
# 특징과 라벨 분리
X = df.drop('EP', axis=1)
Y = df['EP']# 모든 피쳐가 연속형
for i in X.columns:
print(i, len(df[i].unique()))
# 신규 데이터 생성
# 특징이 추가된 데이터를 부착할 데이터
X_added = X.copy()
# 로그, 제곱 관련 변수 추가
# 만약, 범주형 변수와 연속형 변수가 혼합인 경우 나였으면 연속형 변수만 빼서 변수 추가 후 합쳤을듯...
for col in X.columns:
X_added[col + '_squared'] = X[col]**2
X_added[col + '_log'] = np.log(X[col])
X_added.head()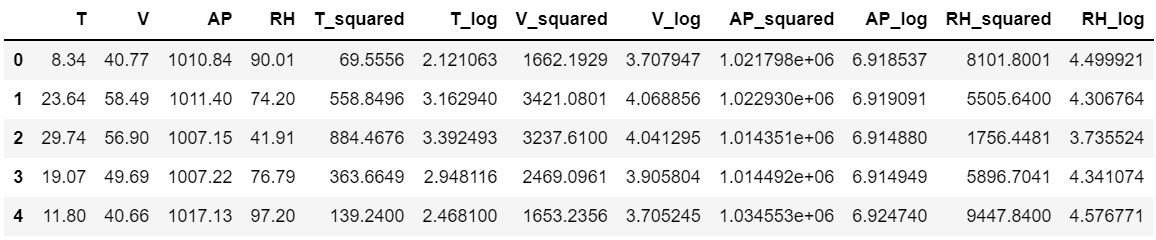
(범주형 변수의 경우 원핫인코딩 후 로그변환을 하게되면 값이 달라져서 원본 데이터 손상이 되고, 제곱을 해도 똑같은 값이므로 연속형 변수만 특징변환?)
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LinearRegression as LR
# 5겹 교차검증 기반의 평가 수행
X_score = -cross_val_score(LR(), X, Y, cv=5, scoring='neg_mean_absolute_error').mean()
X_added_score = -cross_val_score(LR(), X_added, Y, cv=5, scoring='neg_mean_absolute_error').mean()
# 특징을 추가했을 때 성능이 좋아졌다.
print("특징 추가 전: {}, 특징 추가 후: {}".format(X_score, X_added_score))
위 처럼 다양한 변환 방법을 사용하여 특징을 생성한 뒤 특징 선택을 수행
'데이터 전처리 > 머신러닝 모델의 성능 향상을 위한 전처리' 카테고리의 다른 글
| 클래스 불균형 문제 (0) | 2022.12.27 |
|---|---|
| 변수 분포 문제-특징간 스케일 차이 해결하기(스케일링) (0) | 2022.12.26 |
| 변수 분포 문제-변수 치우침 제거 (0) | 2022.12.26 |
| 변수 분포 문제-특징 간 상관성 제거(특징 선택) (0) | 2022.12.25 |
| 변수 분포 문제-이상치 제거 (0) | 2022.12.22 |