'파이썬 머신러닝 완벽가이드 > [4장] 분류' 카테고리의 다른 글
| 부스팅 (0) | 2023.02.10 |
|---|---|
| 배깅 (0) | 2023.02.09 |
| 앙상블 학습 (0) | 2023.02.09 |
| 결정 트리(Decision Tree) (0) | 2023.02.04 |
| 분류(Classification)의 개요 (0) | 2023.02.04 |
| 부스팅 (0) | 2023.02.10 |
|---|---|
| 배깅 (0) | 2023.02.09 |
| 앙상블 학습 (0) | 2023.02.09 |
| 결정 트리(Decision Tree) (0) | 2023.02.04 |
| 분류(Classification)의 개요 (0) | 2023.02.04 |
●분류와 회귀를 둘 다 지원한다.(분류-DecisionTreeClassifier / 회귀-DecisionTreeRegressor)
●결정 트리는 데이터에 있는 규칙을 학습을 통해 자동으로 찾아내 트리(Tree) 기반의 분류 규칙을 만드는 것이다.(If-Else 기반 규칙)
→쉽게 생각하면 스무고개 게임과 유사하다.
●따라서 데이터의 어떤 기준을 바탕으로 규칙을 만들어야 가장 효율적인 분류가 될 것인가가 알고리즘의 성능을 크게 좌우한다.
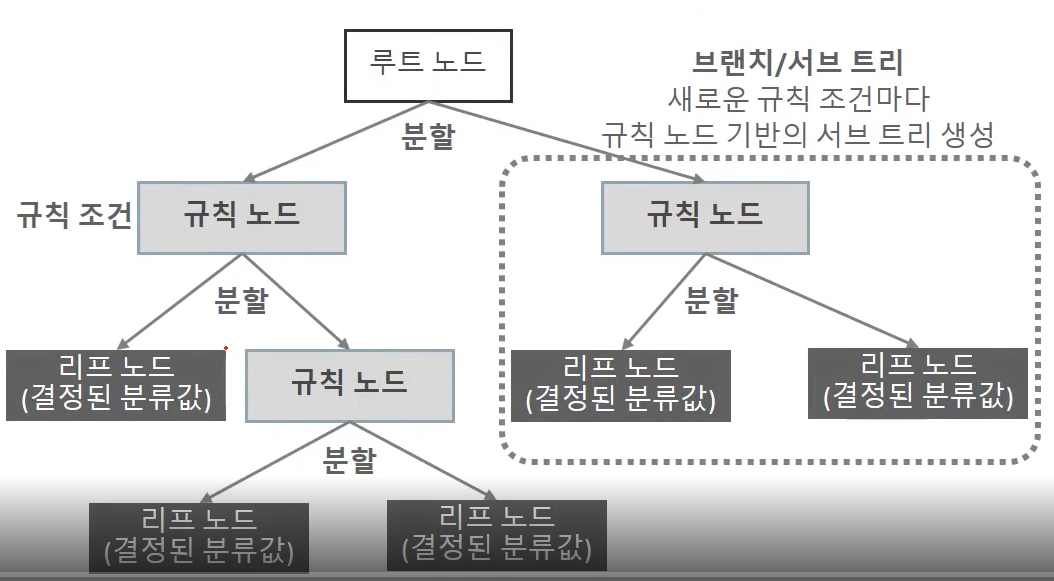
규칙 노드로 표시된 노드는 규칙 조건이 되는 것이고, 리프 노드로 표시된 노드는 결정된 클래스 값이다. 그리고 새로운 규칙 조건마다 서브 트리가 생성된다.
데이터 세트에 피처가 있고 이러한 피처가 결합해 규칙 조건을 만들 때마다 규칙 노드가 만들어진다. 하지만 많은 규칙이 있다는 것은 곧 분류를 결정하는 방식이 더욱 복잡해진다는 얘기이고, 이는 곧 과적합으로 이어지기 쉽다.
즉, 트리의 깊이(depth)가 깊어질수록 결정 트리의 예측 성능이 저하될 가능성이 높다.
그래서 가능한 한 적은 결정 노드로 높은 예측 정확도를 가지려면 데이터를 분류할 때 최대한 많은 데이터 세트가 해당 분류에 속할 수 있도록 결정 노드의 규칙이 정해져야 한다. 이를 위해 어떻게 트리를 분할(split)할 것인가가 중요한데 최대한 균일한 데이터 세트를 구성할 수 있도록 분할하는 것이 필요하다.
균일한 데이터 세트가 어떤 것을 의미하는지 살펴보자.

C의 경우 모두 검은 공으로 구성되므로 데이터가 모두 균일하다. B의 경우 일부 하얀 공을 가지고 있지만, 대부분 검은 공으로 구성되어 다음으로 균일도가 높다. A의 경우는 검은 공 못지않게 많은 하얀 공을 가지고 있어 균일도가 제일 낮다.
이러한 데이터 세트의 균일도는 데이터를 구분하는 데 필요한 정보의 양에 영향을 미친다.
예를 들어, 눈을 가린 채 데이터 세트 C에서 하나의 데이터를 뽑았을 때 데이터에 대한 별다른 정보 없이도 '검은 공'이라고 쉽게 예측할 수 있지만 A의 경우는 상대적으로 균일도가 낮기 때문에 같은 조건에서 데이터를 판단하는데 있어 더 많은 정보가 필요하다.
이렇듯 결정 노드는 정보 균일도가 높은 데이터 세트를 먼저 선택할 수 있도록 규칙 조건을 만든다. 즉, 정보 균일도가 높은 데이터 세트로 쪼개질 수 있도록 조건을 찾아 서브 데이터 세트로 만들고, 다시 이 서브 데이터 세트에서 균일도가 높은 자식 데이터 세트로 쪼개는 방식을 반복하는 방식으로 데이터 값을 예측하게 된다.
(예를 들어 박스 안에 30개의 레고 블록이 있는데, 각 레고 블록은 '형태' 속성으로 동그라미, 네모, 세모, '색깔' 속성으로 노랑, 빨강, 파랑이 있다. 이 중 노랑색 블록의 경우 모두 동그라미로 구성되고 , 빨강과 파랑 블록의 경우는 동그라미, 네모, 세모가 골고루 섞여 있다고 한다면 각 레고 블록을 형태와 색깔 속성으로 분류하고자 할 때 가장 첫 번째로 만들어져야 하는 규칙 조건은 if 색깔 == '노랑색'이 된다. 왜냐하면 노란색 블록이면 모두 노란 동그라미 블록으로 가장 쉽게 예측할 수 있고, 그다음 나머지 블록에 대해 다시 균일도 조건을 찾아 분류하는 것이 가장 효율적인 분류 방식이기 때문이다.)
이러한 정보 균일도를 측정하는 방법은 정보 이득, 지니계수가 있다.
<정보 균일도 측정 방법>
1) 정보 이득(Information Gain)
정보 이득은 엔트로피 개념을 기반으로 한다. 엔트로피는 주어진 데이터 집합의 혼잡도를 의미하는데, 서로 다른 값이 섞여 있으면 엔트로피가 높고, 같은 값이 섞여 있으면 엔트로피가 낮다.
정보 이득 지수는 1에서 엔트로피 지수를 뺀 값으로 '1-엔트로피 지수'이다. 결정 트리는 이 정보 이득 지수로 분할 기준을 정하는데 정보 이득이 높은 속성을 기준으로 분할한다.
(정보 균일도가 높은 데이터 세트로 쪼개질 수 있도록→정보 이득이 높은 속성→엔트로피 낮음→같은 값이 섞여 있음)
2) 지니 계수
지니 계수는 원래 경제학에서 불평등 지수를 나타낼 때 사용하는 계수이다. 0이 가장 평등하고 1로 갈수록 불평등하다.
머신러닝에 적용될 때는 지니 계수가 낮을수록 데이터 균일도가 높은 것으로 해석해 지니계수가 낮은 속성을 기준으로 분할한다.
(정보 균일도가 높은 데이터 세트로 쪼개질 수 있도록→지니계수가 낮은 속성→평등→같은 값이 섞여 있음)
⇛ 결정 트리 알고리즘을 사이킷런에서 구현한 DecisionTreeClassifier는 기본으로 지니 계수를 이용해 데이터 세트를 분할한다. 결정 트리의 일반적인 알고리즘은 데이터 세트를 분할하는 데 가장 좋은 조건, 즉 정보 이득이 높거나 지니계수가 낮은 조건을 찾아서 자식 트리 노드에 걸쳐 반복적으로 분할한 뒤, 데이터가 모두 특정 분류에 속하게 되면 분할을 멈추고 분류를 결정한다.
<결정 트리의 특징>
1) 장점
2) 단점
위의 단점을 설명하자면
피처 정보의 균일도에 따른 룰 규칙으로 서브 트리를 계속 만들다 보면 피처가 많고 균일도가 다양하게 존재할수록 트리의 깊이가 커지고 복잡해질 수 밖에 없다. 결과적으로 복잡한 학습 모델에 이르게 된다. 복잡한 학습 모델은 결국에는 실제 상황에(테스트 데이터 세트) 유연하게 대처할 수 없어서 예측 성능이 떨어질 수밖에 없다.
<Graphviz를 이용한 결정 트리 모델의 시각화>
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings('ignore')
# DecisionTreeClassifier 생성
dt_clf = DecisionTreeClassifier(random_state=156)
# 붓꽃 데이터를 로딩하고, 학습과 테스트 데이터 세트로 분리
iris_data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target,
test_size=0.2, random_state=11)
# DecisionTreeClassifier 학습
dt_clf.fit(X_train, y_train)from sklearn.tree import export_graphviz
# export_graphviz()의 호출 결과로 out_file로 지정된 tree.dot 파일을 생성함
export_graphviz(dt_clf, out_file='tree.dot',class_names=iris_data.target_names,
feature_names=iris_data.feature_names, impurity=True, filled=True)import graphviz
# 위에서 생성된 tree.dot 파일을 Graphviz가 읽어서 주피터 노트북상에서 시각화
with open("tree.dot") as f:
dot_graph = f.read()
graphviz.Source(dot_graph)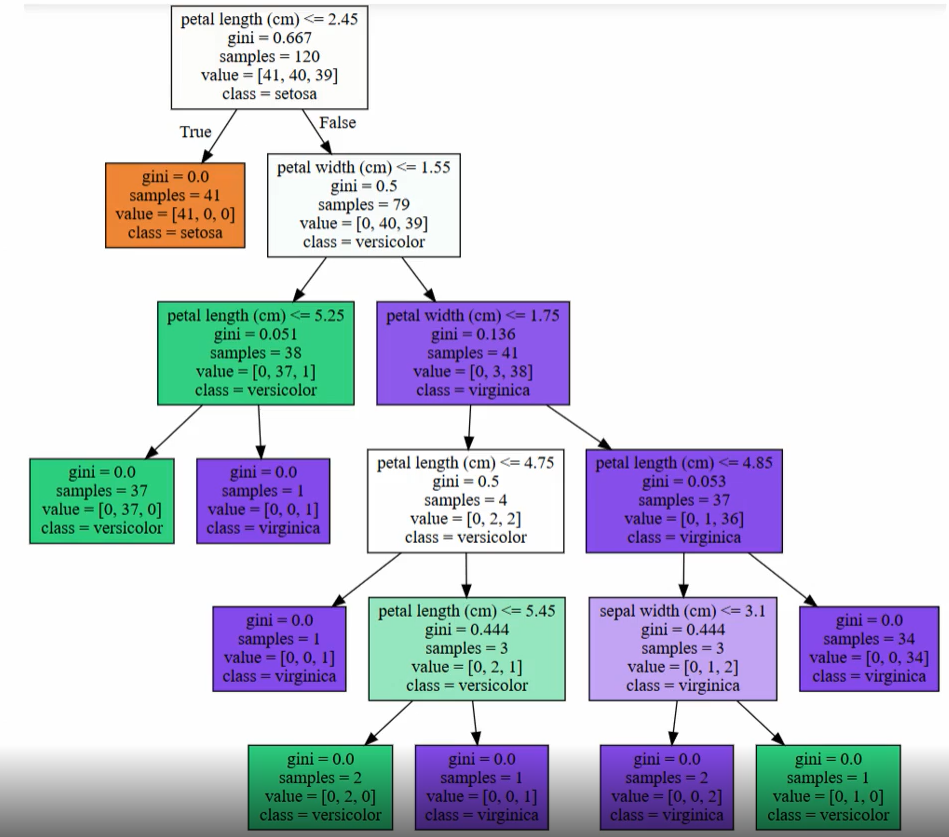
시각화된 결정 트리의 맨 윗부분에서 몇 단계 아래로 내려가 보면서 어떻게 트리가 구성되는지 구체적으로 보겠다.

●petal_length(cm) <= 2.45 와 같이 피처의 조건이 있는 것은 자식 노드를 만들기 위한 규칙 조건이다. 이 조건이 없으면 리프 노드이다.
●gini는 value=[ ]로 주어진 데이터 분포에서의 지니 계수이다.
●samples는 현 규칙에 해당하는 데이터 건수이다.
●value=[ ]는 클래스 값 기반의 데이터 건수이다. 붓꽃 데이터 세트는 클래스 값으로 0, 1, 2를 가지고 있으며, 0:Setosa, 1:Versicolr, 2:Virginica 품종을 가리킨다. 만일 value=[41, 40, 39]라면 클래스 값의 순서로 Setosa 41개, Versicolor 40개, Virginica 39개로 데이터가 구성돼 있다는 의미이다.
●class는 value 리스트내에 가장 많은 건수를 가진 결정값이다.
초록색 노드를 다시 살펴보면 38개의 샘플 데이터 중 Virginica가 단 1개이고, 37개가 Versicolor이지만 Versicolor와 Virginica를 구분하기 위해서 다시 자식 노드를 생성한다. 이처럼 결정 트리는 규칙 생성 로직을 미리 제어하지 않으면 완벽하게 클래스 값을 규별해내기 위해 트리 노드를 계속해서 만들어 간다. 이로 인해 결국 매우 복잡한 규칙 트리가 만들어져 모델이 쉽게 과적합되는 문제점을 가지게 된다.
결정 트리는 이러한 이유로 과적합이 상당히 높은 ML 알고리즘이다. 이 때문에 결정 트리 알고리즘을 제어하는 대부분 하이퍼 파라미터는 복잡한 트리가 생성되는 것을 막기 위한 용도이다.
<결정 트리 파라미터>
max_depth
min_samples_split
min_samples_leaf
max_features
max_leaf_nodes
이제부터 결정 트리의 하이퍼 파라미터 변경에 따른 트리 변화를 보겠다.
⊙max_depth 하이퍼 파라미터 변경에 따른 트리 변화
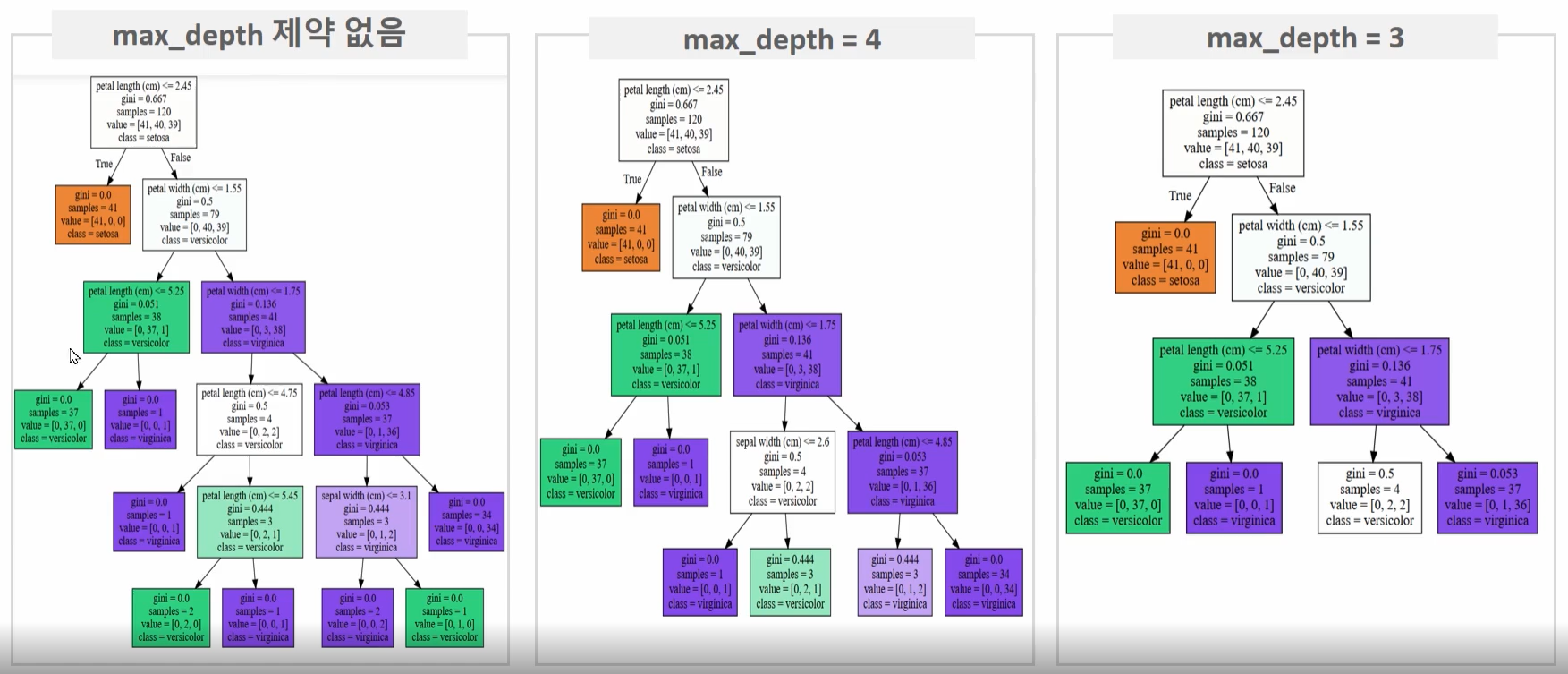
max_depth를 제한 없음에서 3개로 설정하면 트리 깊이가 설정된 max_depth에 따라 줄어들면서 더 간단한 결정 트리가 된다.
⊙min_samples_split 하이퍼 파라미터 변경에 따른 트리 변화

min_samples_split=4로 설정한 경우
맨 아래 리프 노드 중 사선 박스로 표시된 노드를 보면 샘플이 3개인데, 이 노드 안에 value가 [0, 2, 1]과 [0, 1, 2]로 서로 상이한 클래스 값이 있어도 더 이상 분할하지 않고 리프 노드가 되었다.
즉 노드를 분할하기 위한 최소한의 샘플 데이터 수가 4개는 필요한데, 3개밖에 없으므로 더 이상 분할을 하지 않고 리프 노드가 됨을 알 수 있음
→자연스럽게 트리 깊이도 줄었고 더욱 간결한 결정 트리가 만들어졌다.
⊙min_samples_leaf 하이퍼 파라미터 변경에 따른 트리 변화
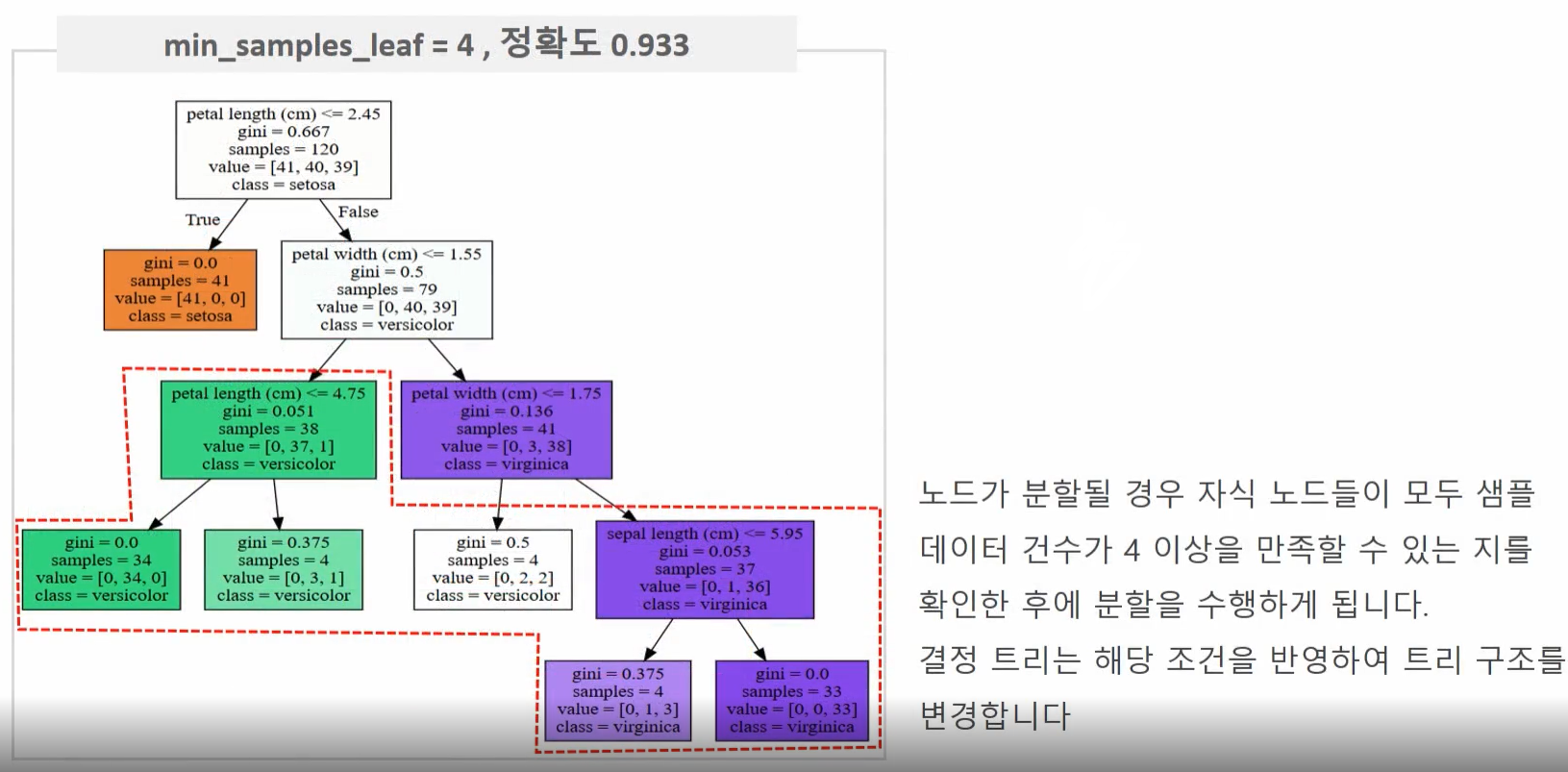
min_samples_leaf=4로 설정한 경우 노드가 분할할 때 왼쪽, 오른쪽 자식 노드가 모두 샘플 데이터 수 4 이상을 가진 노드가 되어야 하므로 디폴트인 1로 설정하는 것보다는 조건을 만족하기 어려워서 상대적으로 적은 횟수로 분할을 수행한다.
→자연스럽게 트리 깊이도 줄었고 더욱 간결한 결정 트리가 만들어졌다.
<피처의 중요 역할 지표: feature_importances_>
사이킷런은 결정 트리 알고리즘이 학습을 통해 규칙을 정하는 데 있어 피처의 중요한 역할 지표를 feature_importances_ 속성으로 제공한다.
●feature_importances_ 값이 높을수록 해당 피처의 중요도가 높다
import seaborn as sns
import numpy as np
%matplotlib inline
# feature importance 추출
print('Feature importances:\n{0}'.format(np.round(dt_clf.feature_importances_, 3)))
# feature별 importance 매핑
for name, value in zip(iris_data.feature_names, dt_clf.feature_importances_):
print('{0}:{1:.3f}'.format(name, value))
# feature importance를 피처별로 시각화하기
sns.barplot(x=dt_clf.feature_importances_, y=iris_data.feature_names)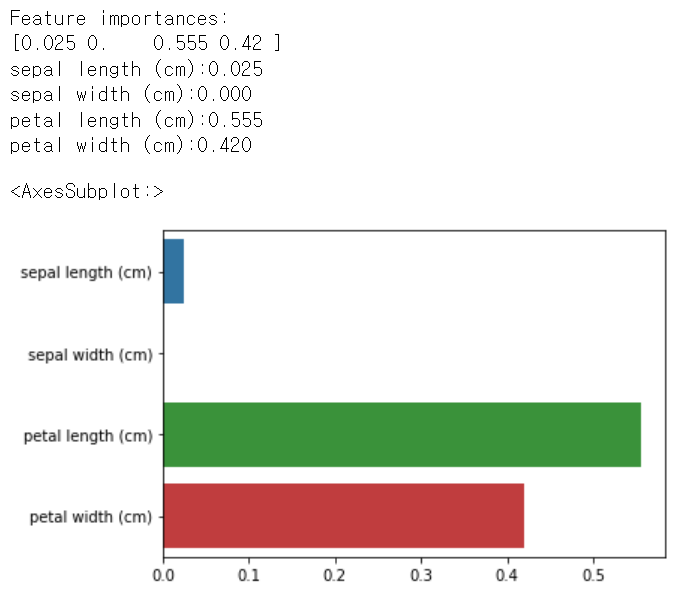
여러 피처들 중 petal length가 가장 피처 중요도가 높음을 알 수 있음
<결정 트리 과적합>
결정 트리가 어떻게 학습 데이터를 분할해 예측을 수행하는지와 이로 인한 과적합 문제를 구체적으로 알아보자!
사이킷런의 make_classification() 함수를 이용해 분류를 위한 임의의 데이터 세트를 만들고 이를 시각화한다.
;make_classification() 함수 참고 자료
from sklearn.datasets import make_classification
import matplotlib.pyplot as plt
%matplotlib inline
plt.title("3 Class values with 2 Features Sample data creation")
# 2차원 시각화를 위해서 feature는 2개, 결정값 클래스는 3가지 유형의 classification 샘플 데이터 생성.
X_features, y_labels = make_classification(n_features=2, n_redundant=0, n_informative=2,
n_classes=3, n_clusters_per_class=1,random_state=0)
# plot 형태로 2개의 feature로 2차원 좌표 시각화, 각 클래스값은 다른 색깔로 표시됨.
plt.scatter(X_features[:, 0], X_features[:, 1], marker='o', c=y_labels, s=25, cmap='rainbow', edgecolor='k')
이제 X_features와 y_labels 데이터 세트를 기반으로 결정 트리를 학습한다. 첫 번째 학습 시에는 결정 트리 생성에 별다른 제약이 없도록 결정 트리의 하이퍼 파라미터를 디폴트로 한 뒤, 결정 트리 모델이 어떠한 결정 기준을 가지고 분할하면서 데이터를 분류하는지 확인할 것이다. 이를 위해 별도의 함수 visualize_boundary()를 생성해 머신러닝 모델이 클래스 값을 예측하는 결정 기준을 색상과 경계로 나타내 모델이 어떻게 데이터 세트를 예측 분류하는지 본다.
import numpy as np
# Classifier의 Decision Boundary를 시각화 하는 함수
def visualize_boundary(model, X, y):
fig,ax = plt.subplots()
# 학습 데이터 scatter plot으로 나타내기
ax.scatter(X[:, 0], X[:, 1], c=y, s=25, cmap='rainbow', edgecolor='k',
clim=(y.min(), y.max()), zorder=3)
ax.axis('tight')
ax.axis('off')
xlim_start , xlim_end = ax.get_xlim()
ylim_start , ylim_end = ax.get_ylim()
# 호출 파라미터로 들어온 training 데이타로 model 학습 .
model.fit(X, y)
# meshgrid 형태인 모든 좌표값으로 예측 수행.
xx, yy = np.meshgrid(np.linspace(xlim_start,xlim_end, num=200),np.linspace(ylim_start,ylim_end, num=200))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape)
# contourf() 를 이용하여 class boundary 를 visualization 수행.
n_classes = len(np.unique(y))
contours = ax.contourf(xx, yy, Z, alpha=0.3,
levels=np.arange(n_classes + 1) - 0.5,
cmap='rainbow', clim=(y.min(), y.max()),
zorder=1)from sklearn.tree import DecisionTreeClassifier
# 특정한 트리 생성 제약이 없도록 하이퍼 파라미터가 디폴트인 결정 트리의 학습과 결정 경계 시각화
dt_clf = DecisionTreeClassifier(random_state=156).fit(X_features, y_labels)
visualize_boundary(dt_clf, X_features, y_labels)
일부 이상치(outlier) 데이터까지 분류하기 위해 분할이 자주 일어나서 결정 기준 경계가 매우 많아졌다.
결정 트리의 기본 하이퍼 파라미터 설정은 리프 노드 안에 데이터가 모두 균일하거나 하나만 존재해야 하는 엄격한 분할 기준으로 인해 결정 기준 경계가 많아지고 복잡해졌다. 이렇게 복잡한 모델은 학습 데이터 세트의 특성과 약간만 다르 형태의 데이터 세트(테스트 데이터 세트)를 예측하면 예측 정확도가 떨어지는 과적합(overfitting)이 발생한다.
# min_samples_leaf=6으로 트리 생성 조건을 제약한 결정 경계 시각화
dt_clf = DecisionTreeClassifier(min_samples_leaf=6, random_state=156).fit(X_features, y_labels)
visualize_boundary(dt_clf, X_features, y_labels)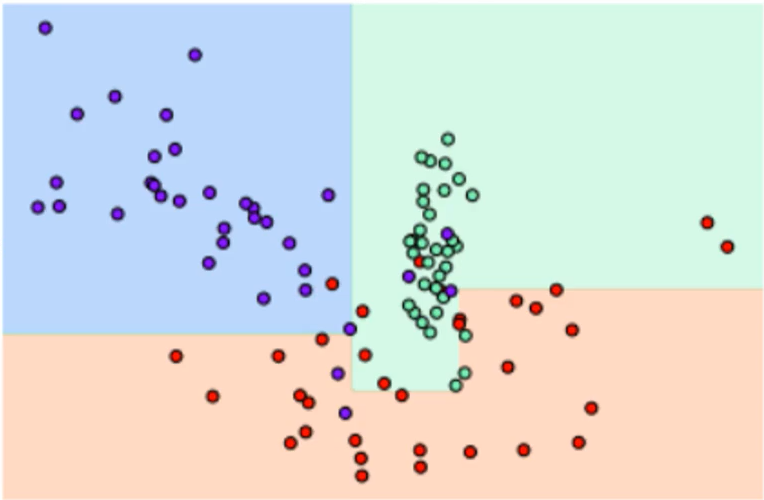
이상치에 크게 반응하지 않으면서 좀 더 일반화된 분류 규칙에 따라 분류됐음을 알 수 있다. 다양한 테스트 데이터 세트를 기반으로 한 결정 트리 모델의 예측 성능은 첫 번째 모델보다는 min_samples_leaf=6으로 트리 생성 조건을 제약한 모델이 더 뛰어날 가능성이 높다. 왜냐하면 테스트 데이터 세트는 학습 데이터 세트와는 다른 데이터 세트인데, 학습 데이터만 지나치게 최적화된 분류 기준은 오히려 테스트 데이터 세트에서 정확도를 떨어뜨릴 수 있는 과적합 문제 때문이다.
| 부스팅 (0) | 2023.02.10 |
|---|---|
| 배깅 (0) | 2023.02.09 |
| 앙상블 학습 (0) | 2023.02.09 |
| 결정 트리 실습 - 사용자 행동 인식 데이터 세트 (0) | 2023.02.09 |
| 분류(Classification)의 개요 (0) | 2023.02.04 |
분류(Classification)는 학습 데이터로 주어진 데이터의 피처와 레이블값(결정값, 클래스값)을 머신러닝 알고리즘으로 학습해 모델을 생성하고, 이렇게 생성된 모델에 새로운 데이터 값이 주어졌을 때 미지의 레이블 값을 예측하는 것
<대표적인 분류 알고리즘>
●베이즈(Bayes) 통계와 생성 모델에 기반한 나이브 베이즈(Naive bayes)
●독립변수와 종속변수의 선형 관계성에 기반한 로지스틱 회귀(Logistic Regression)
●데이터 균일도에 따른 규칙 기반의 결정 트리(Decision Tree)
●개별 클래스 간의 최대 분류 마진을 효과적으로 찾아주는 서포트 벡서 머신(Support Vector Machine)
●근접 거리를 기준으로 하는 최소 근접 알고리즘(K Nearest Neighbor)
●심층 연결 기반의 신경망(Neural Network)
●서로 다른(또는 같은) 머신러닝 알고리즘을 결합한 앙상블(Ensemble)
이번 장에서는 위의 다양한 알고리즘 중에서 앙상블 방법을 집중적으로 다룰것이다.
앙상블의 기본 알고리즘으로 일반적으로 사용하는 것은 결정 트리이다.
결정 트리와 앙상블
●결정 트리는 매우 쉽고 유연하게 적용될 수 있는 알고리즘이다. 또한 데이터의 스케일링이나 정규화 등의 사전 가공의 영향이 매우 적다. 하지만 예측 성능을 향상시키기 위해 복잡한 규칙 구조를 가져야 하며, 이로 인한 과적합(overfitting)이 발생해 반대로 예측 성능이 저하될 수도 있다는 단점이 있다.
●하지만 이런 단점이 앙상블 기법에서는 오히려 장점으로 작용한다. 앙상블은 매우 많은 여러 개의 약한 학습기(즉, 예측 성능이 상대적으로 떨어지는 학습 알고리즘)를 결합해 확률적 보완과 오류가 발생한 부분에 대한 가중치를 계속 업데이트하면서 예측 성능을 향상시키는데, 결정 트리가 좋은 약한 학습기가 되기 때문이다.
앙상블을 학습하기 전에 먼저 결정 트리가 무엇이고 어떤 특성이 있는지 살펴보자!
| 부스팅 (0) | 2023.02.10 |
|---|---|
| 배깅 (0) | 2023.02.09 |
| 앙상블 학습 (0) | 2023.02.09 |
| 결정 트리 실습 - 사용자 행동 인식 데이터 세트 (0) | 2023.02.09 |
| 결정 트리(Decision Tree) (0) | 2023.02.04 |
| f1 score, roc auc (0) | 2023.01.31 |
|---|---|
| 정확도, 정밀도, 재현율 (0) | 2023.01.30 |
4. F1 score
F1 score는 정밀도와 재현율을 결합한 지표이다. F1 score는 정밀도와 재현율이 어느 한쪽으로 치우치지 않는 수치를 나타낼 때 상대적으로 높은 값을 가진다.
이전에 학습한 로지스틱 회귀 기반 타이타닉 생존자 모델을 이용하여 F1 score를 구해보았다.
from sklearn.metrics import f1_score
f1 = f1_score(y_test, pred)
print('F1 스코어:{0:.4f}'.format(f1))
threshold를 변화시키면서 F1 score를 구해볼 것이고, 이전에 get_clf_eval() 함수에 F1 score를 구하는 로직을 추가하였다. 그리고 이전에 get_eval_by_threshold() 함수를 이용해 임계값 0.4 ~ 0.6별로 평가 지표를 구할것이다.
def get_clf_eval(y_test, pred):
confusion = confusion_matrix(y_test, pred)
accuracy = accuracy_score(y_test, pred)
precision = precision_score(y_test, pred)
recall = recall_score(y_test, pred)
# F1 score 추가
f1 = f1_score(y_test, pred)
print('오차 행렬')
print(confusion)
print('정확도:{0:.4f}, 정밀도:{1:.4f}, 재현율:{2:.4f}, F1:{3:.4f}'.format(accuracy, precision, recall, f1))
thresholds = [0.4, 0.45, 0.5, 0.55, 0.6]
pred_proba = lr_clf.predict_proba(X_test)
get_eval_by_threshold(y_test, pred_proba[:,1].reshape(-1,1), thresholds)
F1 score는 threshold가 0.6일 때 가장 좋은 값을 보인다. 하지만 임계값이 0.6인 경우에는 재현율이 크게 감소하니 주의해야 한다.
5. ROC 곡선과 AUC
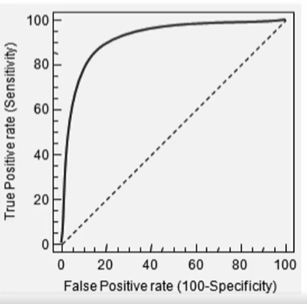
ROC 곡선은 FPR(False Positive Rate)이 변할 때 TPR(True Positive Rate)이 어떻게 변하는지를 나타내는 곡선이다. FPR을 x축으로, TPR을 y축으로 잡으면 FPR의 변화에 따른 TPR의 변화가 곡선 형태로 나타남
분류의 성능 지표로 사용되는 것은 ROC 곡선 면적에 기반한 AUC 값으로 결정한다. AUC(Area Under Curve)값은 ROC 곡선 밑의 면적을 구한 것으로 일반적으로 1에 가까울수록 좋은 수치이다.
→ROC 곡선이 가운데 직선에 가까울수록 면적이 작기 때문에 성능이 떨어지는 것이며, 멀어질수록 면적이 크기 때문에 성능이 뛰어난 것
-TPR은 True Positive Rate의 약자이며, 이는 재현율을 나타낸다.(실제 Positive를 맞게 예측한 비율)
따라서 TPR은 TP / (FN+TP)이다. TPR, 즉 재현율은 민감도로도 불림
-FPR은 실제 Negative를 잘못 예측한 비율을 나타낸다.
즉, 실제는 Negative인데 Positive로 잘못 예측한 비율이다.
따라서 FPR은 FP / (FP+TN)이다.
ROC 곡선은 FPR을 0부터 1까지 변경하면서 TPR의 변화 값을 구해 그리는데, Threshold(분류 결정 임계값)을 변경함으로서 수행할 수 있음
●Threshold를 1로 하면 FPR은 0임
→임계값을 1로 하면 Positive 예측 기준이 매우 높기 때문에 아예 Positive로 예측하지 않아서 FP 값이 0이 되므로 FPR은 0이 됨
●Threshold를 0으로 하면 FPR은 1임
→임계값을 0으로 하면 Positive 예측 기준이 매우 낮기 때문에 전부 Positive로 예측을 해서 아예 Negative 예측이 없음. 그래서 TN 값이 0이 되므로 FPR은 1이 됨
<ROC 곡선 및 AUC 스코어 API>

이전에 정밀도와 재현율에서 학습한 LogisticRegression 객체의 predict_proba() 결과를 다시 이용해 ROC 곡선과 AUC 값을 구해보자
from sklearn.metrics import roc_curve
# 레이블 값이 1일때의 예측 확률을 추출
pred_proba_class1 = lr_clf.predict_proba(X_test)[:,1]
fprs, tprs, thresholds = roc_curve(y_test, pred_proba_class1)
# 반환된 임계값 배열에서 샘플로 데이터를 추출하되, 임계값을 5 step으로 추출
# thresholds[0]는 max(예측확률)+1로 임의 설정됨. 이를 제외하기 위해 np.arange는 1부터 시작
thr_index = np.arange(1, thresholds.shape[0], 5)
print('샘플 추출을 위한 임계값 배열의 index:', thr_index)
print('샘플 index로 추출한 임계값:', np.round(thresholds[thr_index], 2))
# 5 step 단위로 추출된 임계값에 따른 FPR, TPR 값
print('샘플 임계값별 FPR:', np.round(fprs[thr_index], 2))
print('샘플 임계값별 TPR:', np.round(tprs[thr_index], 2))
# roc curve 시각화
def roc_curve_plot(y_test, pred_proba_c1):
# 임계값에 따른 FPR, TPR 값을 반환받음
fprs, tprs, thresholds = roc_curve(y_test, pred_proba_c1)
# ROC 곡선 그리기
plt.plot(fprs, tprs, label='ROC')
# 가운데 랜덤 수준의 대각선 직선 그리기(AUC=0.5)
plt.plot([0, 1], [0, 1], 'k--', label='Random')
# FPR x축의 scale을 0.1 단위로 변경, x와 y축명 설정 등
start, end = plt.xlim()
plt.xticks(np.round(np.arange(start, end, 0.1), 2))
plt.xlim(0, 1); plt.ylim(0, 1)
plt.xlabel('FPR(1-Specificity)'); plt.ylabel('TPR(Recall)')
plt.legend()
roc_curve_plot(y_test, pred_proba[:, 1])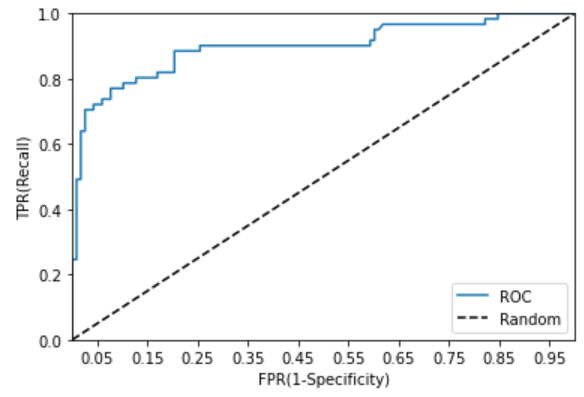
# AUC 값 구하기
from sklearn.metrics import roc_auc_score
pred_proba = lr_clf.predict_proba(X_test)[:, 1]
roc_score = roc_auc_score(y_test, pred_proba)
print('ROC AUC 값:{0:.4f}'.format(roc_score))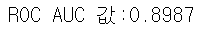
오차행렬, 정확도, 정밀도, 재현율, F1 스코어, ROC AUC 값을 한번에 출력할 수 있는 함수 작성
def get_clf_eval(y_test, pred=None, pred_proba=None):
confusion = confusion_matrix(y_test, pred)
accuracy = accuracy_score(y_test, pred)
precision = precision_score(y_test, pred)
recall = recall_score(y_test, pred)
f1 = f1_score(y_test, pred)
# ROC-AUC 추가
roc_auc = roc_auc_score(y_test, pred_proba)
print('오차 행렬')
print(confusion)
# ROC-AUC print 추가
print('정확도:{0:.4f}, 정밀도:{1:.4f}, 재현율:{2:.4f}, \
F1:{3:.4f}, AUC:{4:.4f}'.format(accuracy, precision, recall, f1, roc_auc))
| 피마 인디언 당뇨병 예측 실습 (0) | 2023.02.04 |
|---|---|
| 정확도, 정밀도, 재현율 (0) | 2023.01.30 |
●이진 분류: 클래스 변수의 상태 공간이 크기가 2인 분류
●다중 분류:클래스 변수의 상태 공간이 크기가 3이상인 분류
각 클래스를 긍정으로 간주하여 평가 지표를 계산한 뒤, 이들의 산술 평균(macro average), 가중 평균(micro average, weighted average)으로 평가한다

1. 정확도
실제 데이터에서 예측 데이터가 얼마나 같은지를 판단하는 지표
●정확도는 직관적으로 모델 예측 성능을 나타내는 평가 지표이다. 하지만 이진 분류의 경우 데이터의 구성에 따라 ML 모델의 성능을 왜곡할 수 있기 때문에 정확도 수치 하나만 가지고 성능을 평가하지 않는다.
●특히 정확도는 불균형한 레이블 값 분포에서 ML 모델의 성능을 판단할 경우, 적합한 평가 지표가 아니다.
●정확도 = (TN+TP) / (TN+FP+FN+TP)
유명한 MNIST 데이터 세트를 변환해 불균형한 데이터 세트로 만든 뒤에 정확도 지표 적용 시 어떤 문제가 발생할 수 있는지 살펴보자.
MNIST 데이터 세트는 0부터 9까지의 숫자 이미지의 픽셀 정보를 가지고 있으며, 이를 기반으로 숫자 Digit를 예측하는데 사용된다. 원래 MNIST 데이터 세트는 레이블 값이 0부터 9까지 있는 다중 분류를 위한 것이다. 이것을 레이블 값이 7인 것만 True, 나머지 값은 모두 False로 변환해 이진 분류 문제로 바꿔 전체 데이터의 10%만 True, 나머지 90%는 False인 불균형한 데이터 세트로 변형한다.
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.base import BaseEstimator # 사이킷런은 BaseEstimator를 상속받으면 맞춤형 형태의 Estimator를 개발자가 생성할 수 있음
from sklearn.metrics import accuracy_score
import numpy as np
import pandas as pd
class MyFakeClassifier(BaseEstimator):
def fit(self, X, y):
pass
# 입력값으로 들어오는 X 데이터 세트의 크기만큼 모두 0값으로 만들어서 반환
def predict(self, X):
return np.zeros((len(X), 1), dtype=bool)
# 사이킷런의 내장 데이터 세트인 load_digits()를 이용해 MNIST 데이터 로딩
digits = load_digits()
# digits 번호가 7번이면 True이고 이를 astype(int)로 1로 변환, 7번이 아니면 False이고 0으로 변환
y = (digits.target == 7).astype(int)
X_train, X_test, y_train, y_test = train_test_split(digits.data, y, random_state=11)# 불균형한 레이블 데이터 분포도 확인
print('레이블 테스트 세트 크기:', y_test.shape)
print('테스트 세트 레이블 0과 1의 분포도')
print(pd.Series(y_test).value_counts())
# MyFakeClassifier로 학습/예측/정확도 평가
fakeclf = MyFakeClassifier()
fakeclf.fit(X_train, y_train)
fakepred = fakeclf.predict(X_test) # 위 코드를 보면 반환값으로 다 0으로 반환→모든 예측을 0으로 하도록 반환
# 실제값과 모든 예측을 0으로 반환한 예측값의 정확도
print('모든 예측을 0으로 하여도 정확도는:{0:.3f}'.format(accuracy_score(y_test, fakepred)))
2. 오차행렬(혼동행렬)
일반적으로 불균형한 레이블을 가지는 이진 분류 모델에서는 많은 데이터 중에서 중점적으로 찾아야 하는 매우 적은 수의 결과값에 Postive를 설정해 1값을 부여하고, 그렇지 않은 경우는 Negative로 0값을 부여하는 경우가 많다.
예를 들어 사기 행위 예측 모델에서는 사기 행위가 Positive 양성으로 1, 정상 행위가 Negative 음성으로 0 값이 결정 값으로 할당되거나 암 검진 예측 모델에서는 암이 양성일 경우 Positive 양성으로 1, 암이 음성일 경우 Negative 음성으로 0값이 할당되는 경우가 일반적이다.
불균형한 이진 분류 데이터 세트에서는 Positive 데이터 건수가 매우 작기 때문에 데이터에 기반한 ML 알고리즘은 Positive보다는 Negative로 예측 정확도가 높아지는 경향이 발생한다(학습 목적식은 정확도를 최대화한다). 10,000건의 데이터 세트에서 9,900건이 Negative이고 100건이 Positive라면 Negative로 예측하는 경향이 더 강해져서 TN은 매우 커지고 TP는 매우 작아진다. 또한 Negative로 예측할 때 정확도가 높기 때문에 FN이 매우 작고, Positive로 예측하는 경우가 작기 때문에 FP 역시 매우 작아진다.
결과적으로 정확도 지표는 불균형한 레이블을 가지는 데이터 세트에서 Positive에 대한 예측 정확도를 판단하지 못한 채 Negative에 대한 예측 정확도만으로도 분류의 정확도가 매우 높게 나타나는 수치적인 판단 오류를 일으키게 된다.
정확도는 분류 모델의 성능을 측정할 수 있는 하나의 요소일 뿐이다. 앞에서도 말했듯 불균형한 데이터 세트에서 정확도만으로는 모델 신뢰도가 떨어질 수 있는 사례가 많기 때문에 불균형한 데이터 세트에서 정확도보다 더 선호되는 평가 지표인 정밀도(Precision)와 재현율(Recall)을 더 선호하는 측면이 있다.
3. 정밀도와 재현율
정밀도와 재현율은 Positive 데이터 세트의 예측 성능에 좀 더 초점을 맞춘 평가 지표이다.
●정밀도는 예측을 Positive로 한 대상 중에 예측과 실제 값이 Positive로 일치한 데이터의 비율
정밀도 = TP / (FP+TP)
●재현율은 실제 값이 Positive인 대상 중에 예측과 실제 값이 Positive로 일치한 데이터의 비율
재현율 = TP / (FN+TP)
정밀도와 재현율 지표의 중요성은 비즈니스의 특성에 따라 달라질 수 있다.
1) 재현율이 상대적으로 더 중요한 지표인 경우는 실제 Positive 양성인 데이터 예측을 Negative로 잘못 판단하게 되면 업무상 큰 영향이 발생하는 경우: 암 진단, 금융사기 판별
2) 정밀도가 상대적으로 더 중요한 지표인 경우는 실제 Negative 음성인 데이터 예측을 Positive 양성으로 잘못 판단하게 되면 업무상 큰 영향이 발생하는 경우: 스팸 메일 판별
→일반적으로 재현율이 정밀도보다 상대적으로 중요한 업무가 많다. 즉, 보통은 위음성비용(FN)이 위양성비용(FP)보다 훨씬 크다.(예시- 암 진단: 위양성 비용(정상인→암환자) vs 위음성 비용(암환자→정상인))
재현율과 정밀도의 공식을 살펴보면 재현율과 정밀도 모두 TP를 높이는 데 동일하게 초점을 맞추지만, 재현율은 FN(위음성비용)을 낮추는데, 정밀도는 FP(위양성비용)를 낮추는데 초점을 맞춤
from sklearn.metrics import *
def get_clf_eval(y_test, pred):
confusion = confusion_matrix(y_test, pred)
accuracy = accuracy_score(y_test, pred)
precision = precision_score(y_test, pred)
recall = recall_score(y_test, pred)
print('오차행렬')
print(confusion)
print('정확도:{0:.4f}, 정밀도:{1:.4f}, 재현율:{2:.4f}'.format(accuracy, precision, recall))import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
titanic_df = pd.read_csv('titanic_train.csv')
y_titanic_df = titanic_df['Survived']
X_titanic_df = titanic_df.drop('Survived', axis=1)
X_titanic_df = transform_features(X_titanic_df)
X_train, X_test, y_train, y_test = train_test_split(X_titanic_df, y_titanic_df, test_size=0.2, random_state=11)
lr_clf = LogisticRegression(solver='liblinear')
lr_clf.fit(X_train, y_train)
pred = lr_clf.predict(X_test)
get_clf_eval(y_test, pred)
<정밀도/재현율 트레이드오프>
분류하려는 업무의 특성상 정밀도 또는 재현율이 특별히 강조돼야 할 경우 분류의 결정 임계값(Threshold)을 조정해 정밀도 또는 재현율의 수치를 높일 수 있다. 하지만 정밀도와 재현율은 상호 보완적인 평가 지표이기 때문에 어느 한 쪽을 강제로 높이면 다른 하나의 수치는 떨어지기 쉽다. 이를 정밀도/재현율의 트레이드오프(Trade-off)라고 부른다.
사이킷런의 분류 알고리즘은 예측 데이터가 특정 레이블에 속하는지를 계산하기 위해 먼저 개별 레이블별로 결정 확률을 구한다. 그리고 예측 확률이 큰 레이블값으로 예측하게 된다. 예를 들어 특정 데이터가 0이 될 확률이 10%, 1이 될 확률이 90%로 예측됐다면 최종 예측은 1로 예측한다. 일반적으로 분류에서는 분류 결정 임계값을 0.5, 즉 50%로 정하고 이 기준값보다 확률이 크면 Positive, 작으면 Negative로 결정한다.
개별 레이블별로 결정 확률을 반환하는 predict_proba() 메서드를 이용한다.
predict() 메서드와 유사하지만 단지 반환 결과가 예측 결과 클래스값이 아닌 예측 확률 결과이다.
이진 분류에서 predict_proba()를 수행해 반환되는 ndarray는 첫 번째 컬럼이 클래스 값 0에 대한 예측 확률, 두 번째 컬럼이 클래스 값 1에 대한 예측 확률이다.
# 위의 타이타닉 예제 이어서 실행
pred_proba = lr_clf.predict_proba(X_test)
pred = lr_clf.predict(X_test)
print('pred_proba()결과 shape:{0}'.format(pred_proba.shape))
print('pred_proba array에서 앞 3개만 추출\n:', pred_proba[:3])
# 예측 확률 array와 예측 결과값 array를 병합해 예측 확률과 예측 결과값을 한눈에 확인
pred_proba_result = np.concatenate([pred_proba, pred.reshape(-1,1)], axis=1)
print('예측 확률이 큰 레이블값으로 예측\n', pred_proba_result[:3])
지금부터 분류 결정 임계값을 조절해 정밀도와 재현율의 성능 수치를 상호 보완적으로 조정해보자!
사이킷런의 Binarizer 클래스에서 threshold를 조절해 진행함. threshold보다 같거나 작으면 0값으로, 크면 1값으로 반환
● threshold=0.5
# 분류 결정 임계값을 0.5로 설정했을 때
from sklearn.preprocessing import Binarizer
# Binarizer의 threshold 설정값. 분류 결정 임계값
custom_threshold = 0.5
# predict_proba() 반환값의 두 번째 컬럼, 즉 Positive 클래스 컬럼 하나만 추출해 Binarizer를 적용
pred_proba_1 = pred_proba[:,1].reshape(-1,1)
binarizer = Binarizer(threshold=custom_threshold).fit(pred_proba_1)
custom_predict = binarizer.transform(pred_proba_1)
get_clf_eval(y_test, custom_predict)
일반적으로 분류에서는 분류 경정 임계값을 0.5, 즉 50%로 정하고 이 기준값보다 확률이 크면 Positive, 작으면 Negative로 결정하기 때문에 threshold를 0.5로 설정했으므로 앞에서 타이타닉 데이터로 학습된 로지스틱 회귀 Classifier 객체에서 호출된 predict()로 계산된 지표 값과 정확히 같다.
● threshold=0.4
# 분류 결정 임계값을 0.4로 설정했을 때
custom_threshold = 0.4
pred_proba_1 = pred_proba[:,1].reshape(-1,1)
binarizer = Binarizer(threshold=custom_threshold).fit(pred_proba_1)
custom_predict = binarizer.transform(pred_proba_1)
get_clf_eval(y_test, custom_predict)
임계값을 낮추니 재현율 값이 올라가고 정밀도가 떨어졌다. 왜냐하면 분류 결정 임계값은 Postive 예측값을 결정하는 확률의 기준으로 확률이 0.5가 아닌 0.4부터 Positive로 예측을 더 너그럽게 하기 때문에 임계값을 낮출수록 True인 1 값이 많아지기 때문이다.

Positive 예측값이 많아지면, 양성 예측을 많이 하다 보니 실제 양성을 음성으로 예측하는 횟수인 FN이 상대적으로 줄어들기 때문에 재현율 값이 높아지고, 양성 예측을 많이 하다 보니 FP가 커지기 때문에 정밀도 값이 낮아짐(공식 생각)
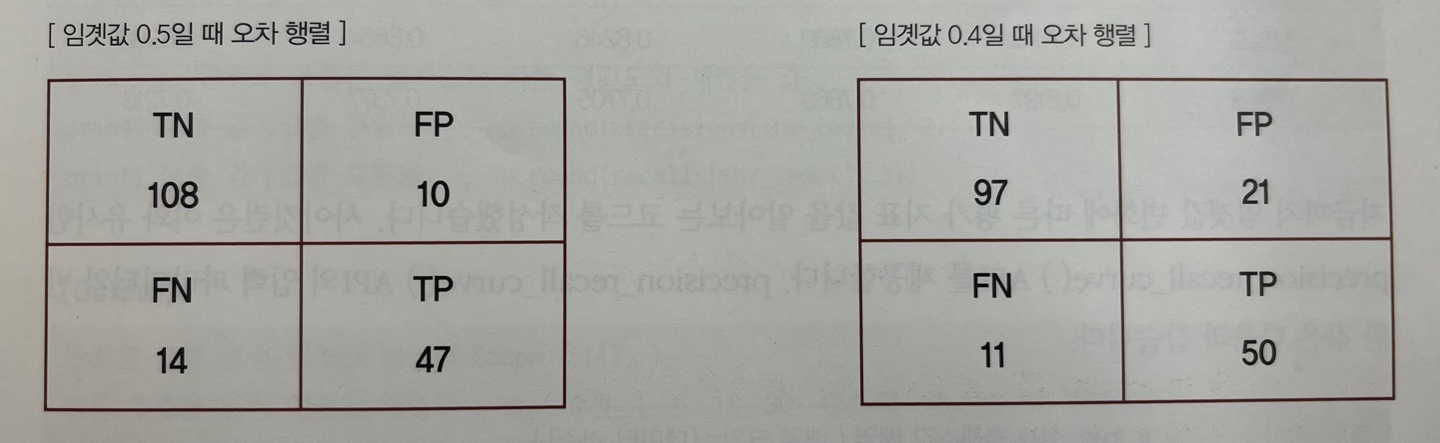
임계값이 낮아지면서 재현율이 0.770에서 0.820으로 좋아졌고, 정밀도는 0.825에서 0.704로 나빠졌다. 그리고 정확도도 0.866에서 0.821로 나빠졌다.
● threshold=0.4 ~ 0.6 (in steps of 0.05)
# 분류 결정 임계값을 0.4 ~ 0.6(in stpes of 0.05)로 설정했을 때
# 테스트를 수행할 모든 임계값을 리스트 객체로 저장
thresholds = [0.4, 0.45, 0.5, 0.55, 0.60]
def get_eval_by_threshold(y_test, pred_proba_c1, thresholds):
# thresholds list객체 내의 값을 차례로 iteration하면서 evaluation 수행
for custom_threshold in thresholds:
binarizer = Binarizer(threshold=custom_threshold).fit(pred_proba_c1)
custom_predict = binarizer.transform(pred_proba_c1)
print('임계값:', custom_threshold)
print('-'*60)
get_clf_eval(y_test, custom_predict)
print('='*60)
get_eval_by_threshold(y_test, pred_proba[:,1].reshape(-1,1), thresholds)
임계값이 0.45일 경우에 디폴트 0.5인 경우와 비교해서 정확도가 약간 감소했고 정밀도도 약간 감소했으나 재현율이 올랐다. 만약 재현율을 향상시키면서 다른 수치를 어느 정도 감소시켜야 하는 경우라면 임계값은 0.45가 가장 적당할 것이다.
★precision_reacall_curve()★
사이킷런은 threshold 변화에 따른 정밀도와 재현율을 구할 수 있게 해주는 precision_recall_curve() API를 제공한다.
- 입력 파라미터
- 반환값
from sklearn.metrics import precision_recall_curve
# 레이블 값이 1일때의 예측 확률을 추출
pred_proba_class1 = lr_clf.predict_proba(X_test)[:,1]
# 실제값 데이터 세트와 레이블 값이 1일때의 예측 확률을 precision_recall_curve 인자로 입력
precisions, recalls, thresholds = precision_recall_curve(y_test, pred_proba_class1)
print('반환된 분류 결정 임계값 배열의 shape:', thresholds.shape)
print('반환된 precisions 배열의 shape:', precisions.shape)
print('반환된 recalls 배열의 shape:', recalls.shape)
print('thresholds 5 sample:', thresholds[:5])
print('precisions 5 sample:', precisions[:5])
print('recalls 5 sample:', recalls[:5])
print('-'*60)
# 반환된 임계값 배열 크기가 165건이므로 샘플로 11건만 추출하되, 임계값을 16 step으로 추출
thr_index = np.arange(0, thresholds.shape[0], 16)
print('샘플 추출을 위한 임계값 배열의 index 11개:', thr_index)
print('샘플용 11개의 임계값:', np.round(thresholds[thr_index], 2))
# 16 step 단위로 추출된 임계값에 따른 정밀도와 재현율 값
print('샘플 임계값별 정밀도:', np.round(precisions[thr_index], 2))
print('샘플 임계값별 재현율:', np.round(recalls[thr_index], 2))
결과를 보면 threshold가 증가할수록 정밀도는 높아지나 재현율은 낮아지는 것을 알 수 있다.
precision_recall_curve() API는 threshold에 따른 정밀도와 재현율의 변화를 시각화하는데 이용할 수 있다.
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
%matplotlib inline
def precision_recall_curve_plot(y_test, pred_proba_c1):
# threshold ndarray와 이 threshold에 따른 정밀도, 재현율 ndarray 추출
precisions, recalls, thresholds = precision_recall_curve(y_test, pred_proba_c1)
# x축을 threshold값으로, y축은 정밀도, 재현율 값으로 각각 plot 수행. 정밀도는 점선으로 표시
plt.figure(figsize=(8,6))
threshold_boundary = thresholds.shape[0]
plt.plot(thresholds, precisions[0:threshold_boundary], linestyle='--', label='precision')
plt.plot(thresholds, recalls[0:threshold_boundary], label='recall')
# threshold 값 x축의 scale을 0.1 단위로 변경
start, end = plt.xlim()
plt.xticks(np.round(np.arange(start, end, 0.1), 2))
# x축, y축 label과 legend, 그리고 grid 설정
plt.xlabel('Threshold value'); plt.ylabel('Precision and Recall value')
plt.legend(); plt.grid()
plt.show()
precision_recall_curve_plot(y_test, lr_clf.predict_proba(X_test)[:,1])
그래프에서 보다시피 정밀도와 재현율에 trade-off가 존재하며 로지스틱 회귀 기반의 타이타닉 생존자 예측 모델의 경우 약 0.45 정도의 threshold에서 정밀도와 재현율이 비슷해지는 것을 볼 수 있다.
→threshold에 따른 정밀도와 재현율은 업무 환경에 맞게 상호 보완할 수 있는 수준에서 적용돼야 한다.
이처럼 정밀도와 재현율 성능 수치도 어느 한 쪽만 참조하면 극단적인 수치 조작이 가능하다. 따라서 정밀도와 재현율 중 하나만 스코어가 좋고 다른 하나는 스코어가 나쁜 분류는 성능이 좋지 않은 분류로 간주할 수 있다.
⇛그래서 정밀도와 재현율의 수치가 적절하게 조합돼 분류의 종합적인 성능 평가에 사용될 수 있는 평가 지표인
'F1 score'가 있다!!
| 피마 인디언 당뇨병 예측 실습 (0) | 2023.02.04 |
|---|---|
| f1 score, roc auc (0) | 2023.01.31 |
| 인코딩, 스케일링, 로그변환 익히기 (0) | 2023.01.25 |
|---|---|
| 사이킷런 기본 익히기, 교차검증 익히기 (0) | 2023.01.23 |
데이터 전처리
범주형 변수를 처리하는 데이터 인코딩, 서로 다른 변수의 값 범위를 일정한 수준으로 맞추는 작업인 스케일링에 대해 알아본다. 더 다양하고 구체적인 데이터 전처리는 '데이터 전처리' 카테고리를 참고한다.
데이터 인코딩
사이킷런의 머신러닝 알고리즘은 문자열 값을 입력값으로 허용하지 않는다. 그래서 모든 문자열 값은 인코딩돼서 숫자 형으로 변환해야 한다. 여기서 문자열 피처는 범주형 변수, 코드화된 범주형 변수를 의미한다.
1) 레이블 인코딩(Label encoding)
from sklearn.preprocessing import LabelEncoder
items = ['TV', '냉장고', '전자레인지', '컴퓨터', '선풍기', '선풍기', '믹서', '믹서']
# LabelEncoder를 객체로 생성한 후, fit()과 transform()으로 레이블 인코딩 수행
encoder = LabelEncoder()
encoder.fit(items)
labels = encoder.transform(items)
print('인코딩 변환값:', labels)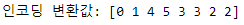
# 문자열 값이 어떤 숫자 값으로 인코딩됐는지 확인 -> LabelEncoder 객체의 classes_
print('인코딩 클래스:', encoder.classes_)
# TV:0, 냉장고:1, 믹서:2, 선풍기:3, 전자레인지:4, 컴퓨터:5
# 인코딩된 값을 다시 디코딩 -> LabelEncoder 객체의 inverse_transform()
print('디코딩 원본값:', encoder.inverse_transform([4, 5, 2, 0, 1, 1, 3, 3]))
레이블 인코딩은 간단하게 문자열 값을 숫자형 값으로 변환하지만 숫자 값의 대소관계가 작용하기 때문에 몇몇 ML 알고리즘에서 예측 성능이 떨어지는 경우가 발생할 수 있다.
예를들어 냉장고가 1, 믹서가 2로 변환되면, 1보다 2가 더 큰 값이므로 특정 ML 알고리즘에서 가중치가 더 부여되거나 더 중요하게 인식할 가능성이 발생한다. 하지만 냉장고와 믹서의 숫자 변환 값은 단순 코드이지 숫자 값에 따른 순서나 중요도로 인식돼서는 안된다.
이러한 특성 때문에 레이블 인코딩은 선형회귀와 같은 ML 알고리즘에는 적용X, 트리 계열의 ML 알고리즘은 숫자의 이러한 특성을 반영하지 않으므로 레이블 인코딩도 별문제가 없음
→레이블 인코딩의 이러한 문제점을 해결하기 위한 인코딩 방식이 "원-핫 인코딩"
2) 원-핫 인코딩(One-Hot Encoding)
원-핫 인코딩은 피처 값의 유형에 따라 새로운 피처를 추가해 고유 값에 해당하는 컬럼에만 1을 표시하고 나머지 컬럼에는 0을 표시하는 방식
●주의점: 입력값으로 2차원 데이터가 필요, OneHotEncoder를 이용해 변환한 값이 희소행렬(sparse matrix) 형태이므로 이를 다시 toarray() 메서드를 이용해 밀집행렬(dense matrix)로 변환해야 함
from sklearn.preprocessing import OneHotEncoder
import numpy as np
items = ['TV', '냉장고', '전자레인지', '컴퓨터', '선풍기', '선풍기', '믹서', '믹서']
# 2차원 ndarray로 변환
items = np.array(items).reshape(-1,1)
# OneHotEncoder를 객체로 생성한 후, fit()과 transform()으로 원-핫 인코딩 수행
oh_encoder = OneHotEncoder()
oh_encoder.fit(items)
oh_labels = oh_encoder.transform(items)
# OneHotEncoder로 변환한 결과는 희소행렬이므로 toarray()를 이용해 밀집행렬로 변환
print('원-핫 인코딩 데이터')
print(oh_labels.toarray())
print('원-핫 인코딩 데이터 차원')
print(oh_labels.shape)
판다스에는 원-핫 인코딩을 더 쉽게 지원하는 get_dummies()가 있음
import pandas as pd
df = pd.DataFrame({'items':['TV', '냉장고', '전자레인지', '컴퓨터', '선풍기', '선풍기', '믹서', '믹서']})
pd.get_dummies(df)
스케일링
스케일링은 서로 다른 피처의 값 범위를 일정한 수준으로 맞추는 작업으로 대표적인 방법인 표준화, 정규화가 있음
●표준화(Standardization)
표준화는 데이터의 피처 각각이 평균이 0이고 분산이 1인 가우시안 정규분포를 가진 값으로 변환하는 것

●정규화(Normalization)
정규화는 서로 다른 피처의 크기를 통일하기 위해 크기를 모두 최소 0 ~ 최대 1의 값으로 변환하는 것

사이킷런에서 제공하는 스케일링 클래스인 StandardScaler, MinMaxScaler를 알아보자!
1) StandardScaler
표준화를 쉽게 지원하는 클래스로, 개별 피처를 평균이 0이고, 분산이 1인 가우시안 정규분포를 가진 값으로 변환
(Scaler 클래스의 fit(), transform()은 2차원 이상 데이터만 가능하다!!)
from sklearn.datasets import load_iris
import pandas as pd
# 붓꽃 데이터 세트를 로딩
iris = load_iris()
iris_df = pd.DataFrame(iris.data, columns=iris.feature_names)
print('feature들의 평균값')
print(iris_df.mean())
print('\nfeature들의 분산값')
print(iris_df.var())
from sklearn.preprocessing import StandardScaler
# StandardScaler 객체 생성
scaler = StandardScaler()
# StandardScaler로 데이터 세트 변환. fit()과 transform() 호출
scaler.fit(iris_df)
iris_scaled = scaler.transform(iris_df)
# transform()시 스케일 변환된 데이터 세트가 ndarray로 반환돼 이를 DataFrame으로 변환
iris_df_scaled = pd.DataFrame(iris_scaled, columns=iris.feature_names)
print('feature들의 평균값')
print(iris_df_scaled.mean())
print('\nfeature들의 분산값')
print(iris_df_scaled.var())
2) MinMaxScaler
정규화를 쉽게 지원하는 클래스로, 서로 다른 피처의 크기를 통일하기 위해 데이터값을 0과 1 사이의 범위 값으로 변환(음수 값이 있으면 -1에서 1값으로 변환)
(Scaler 클래스의 fit(), transform()은 2차원 이상 데이터만 가능하다!!)
from sklearn.preprocessing import MinMaxScaler
# MinMaxScaler 객체 생성
scaler = MinMaxScaler()
# MinMaxScaler로 데이터 세트 변환. fit()과 transform() 호출
scaler.fit(iris_df)
iris_scaled = scaler.transform(iris_df)
# transform()시 스케일 변환된 데이터 세트가 ndarray로 반환돼 이를 DataFrame으로 변환
iris_df_scaled = pd.DataFrame(iris_scaled, columns=iris.feature_names)
print('feature들의 최솟값')
print(iris_df_scaled.min())
print('\nfeautre들의 최댓값')
print(iris_df_scaled.max())
참고로 MinMaxScaler 객체에서 feature_range 인자를 활용해 데이터값의 범위를 조정할 수 있음
★학습 데이터와 테스트 데이터의 스케일링 변환 시 유의점★
fit()은 데이터 변환을 위한 기준 정보를 기억하고 transform()은 이렇게 설정된 정보를 이용해 데이터를 변환함
그런데 학습 데이터 세트와 테스트 데이터 세트에 이 fit()과 transfrom()을 적용할 때 주의가 필요하다.
→다른 전처리 객체도 마찬가지임!!!(SimpleImputer, KNNImputer 등등)
Scaler 객체를 이용해 학습 데이터 세트로 fit()과 transform()을 적용하면 테스트 데이터 세트로는 다시 fit()을 수행하지 않고 학습 데이터 세트로 fit()을 수행한 결과를 이용해 transform() 변환을 적용해야 한다.
즉, 학습 데이터로 fit()이 적용된 스케일링 기준 정보를 그대로 테스트 데이터에 적용해야 하며, 그렇지 않고 테스트 데이터로 다시 새로운 스케일링 기준 정보를 만들게 되면 학습 데이터와 테스트 데이터의 스케일링 기준 정보가 서로 달라지기 때문에 올바른 예측 결과를 도출하지 못한다.
아래 예시를 통해 테스트 데이터에 fit()을 적용할 때 어떠한 문제가 발생하는지 알아보자~
from sklearn.preprocessing import MinMaxScaler
import numpy as np
# 학습 데이터는 0부터 10까지, 테스트 데이터는 0부터 5까지 값을 가지는 데이터 세트로 생성
# Scaler 클래스의 fit(), transform()은 2차원 이상 데이터만 가능하므로 reshape(-1,1)로 차원 변경
train_array = np.arange(0,11).reshape(-1,1)
test_array = np.arange(0,6).reshape(-1,1)# MinMaxScaler를 이용해 학습 데이터 변환
scaler = MinMaxScaler() # MinMaxScaler 객체에 별도의 feature_range 파라미터 값을 지정하지 않으면 0~1 값으로 변환
scaler.fit(train_array)
train_scaled = scaler.transform(train_array)
print('원본 train_array 데이터:', np.round(train_array.reshape(-1), 2))
print('Scale된 train_array 데이터:', np.round(train_scaled.reshape(-1), 2))
# MinMaxScaler를 이용해 테스트 데이터 변환
scaler.fit(test_array)
test_scaled = scaler.transform(test_array)
print('원본 test_array 데이터:', np.round(test_array.reshape(-1), 2))
print('Scale된 test_array 데이터:', np.round(test_scaled.reshape(-1), 2))
출력 결과를 확인하면 학습 데이터와 테스트 데이터의 스케일링이 맞지 않음을 알 수 있다. 테스트 데이터의 경우 최솟값 0, 최댓값 5이므로 1/5로 스케일링된다. 따라서 원본값 1은 0.2로 원본값 5는 1로 변환이 된다. 앞서 학습 데이터는 스케일링 변환으로 원본값 2가 0.2로 원본값 10이 1로 변환됐다.
→머신러닝 모델은 학습 데이터를 기반으로 학습되기 때문에 반드시 테스트 데이터는 학습 데이터의 스케일링 기준에 따라야 하며, 테스트 데이터의 1 값은 학습 데이터와 동일하게 0.1 값으로 변환돼야 한다. 따라서 테스트 데이터에 다시 fit()을 적용해서는 안되며 학습 데이터로 이미 fit()이 적용된 Scaler 객체를 이용해 transform()으로 변환해야 한다.
다음은 맞는 방법인 테스트 데이터에 fit()을 호출하지 않고 학습 데이터로 fit()을 수행한 MinMaxScaler 객체의 transform()을 이용해 데이터를 변환해보자
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(train_array)
train_scaled = scaler.transform(train_array)
test_scaled = scaler.transform(test_array)
print('원본 train_array 데이터:', np.round(train_array.reshape(-1), 2))
print('Scale된 train_array 데이터:', np.round(train_scaled.reshape(-1), 2))
print('\n원본 test_array 데이터:', np.round(test_array.reshape(-1), 2))
print('Scale된 test_array 데이터:', np.round(test_scaled.reshape(-1), 2))
스케일링 변환 시 유의할 점을 요약하면
첫째, 가능하다면 전체 데이터의 스케일링 변환을 적용한 뒤 학습과 테스트 데이터로 분리
둘째, 1이 여의치 않다면 테스트 데이터 변환 시에는 fit()을 적용하지 않고 학습 데이터로 이미 fit()된 Scaler 객체를 이용해 transform()으로 변환
전처리와 데이터 분할 - 인프런 | 질문 & 답변
선생님, 안녕하세요. 스케일링 파트를 보다가 의문점이 생겨서 문의 드렸습니다. 가능하다면 전체 데이터의 스케일링 변환을 적용한 뒤 학습/테스트 데이터로 분리 하라고 하셨는데 스케일링
www.inflearn.com
로그변환
●log변환은 왜곡된 분포를 가진 피처를 비교적 정규분포에 가깝게 변환 → 변수 치우침을 해결하는 대표적인 처리 방법
●log변환은 로그를 취하는 순간 그 수는 진수가 되어버리니 값이 작아지기 때문에 큰 수치를 같은 비율의 작은 수치로 변환하기 때문에 데이터 분포도의 왜곡을 상당 수준 개선
●넘파이의 log1p() 함수를 이용하여 적용이 가능
로그변환과 스케일링의 차이
딱 정해서 말씀드리면, 개별 feature, 또는 target의 분포도가 skew가 심하면 log 변환을 합니다. Standard Scaler는 일반적으로 선형기반의 머신러닝의 입력 (전체) 데이터들에 대해서 다 적용합니다. 보통 scaling은 전체 feature들에(카테고리성 피처 제외) 다 적용합니다.
Skew가 심하면 로그 변환, 전체 데이터의 스케일링을 표준 정규 분포 형태로 맞추고 싶다면 Standard Scaler를 적용합니다(선형 기반의 머신러닝의 입력에서 MinMax나 Standard scaler를 선호는 합니다)
| 타이타닉 생존자 예측 실습 (0) | 2023.01.28 |
|---|---|
| 사이킷런 기본 익히기, 교차검증 익히기 (0) | 2023.01.23 |