거리 기반 병합이 필요한 경우
지역이 포함되는 문제에서 주소나 위치 변수 등을 기준으로 거리가 가까운 레코드 및 관련 통계치를 통합해야 하는 경우가 종종 있다.
이런 경우
첫째, 각 데이터에 포함된 레코드 간 거리를 나타내는 거리 행렬을 생성하고
둘째, 거리 행렬의 행 혹은 열 기준 최소값을 가지는 인덱스를 바탕으로 이웃을 탐색한 뒤
셋째, 이웃을 기존 데이터에 부착하는 방식으로 해결한다.

- 관련 문법: scipy.spatial.distance.cdist
두 개의 행렬을 바탕으로 거리 행렬을 반환하는 함수이다.
-주요 입력
▷XA: 거리 행렬 계산 대상인 행렬(ndarray 및 DataFrame)로, 함수 출력의 행에 해당한다.
▷XB: 거리 행렬 계산 대상인 행렬(ndarray 및 DataFrame)로, 함수 출력의 열에 해당한다.
▷metric: 거리 척도('cityblock', 'correlation', 'cosine', 'euclidean', 'jaccard', 'matching' 등)

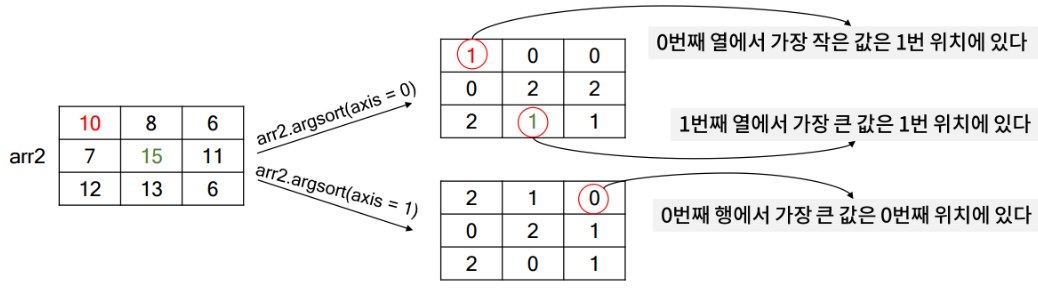
- 관련 문법: ndarray.argsort()
작은 값부터 순서대로 데이터의 위치를 반환하는 함수로, 이웃을 찾는데 주로 활용되는 함수이다.
-주요 입력
▷axis

1차원의 경우 axis 키워드가 작동하지 않는다.
## 코드 실습 ##
import os
os.chdir(r"C:\Users\82102\Desktop\데이터전처리\머신러닝을 위한 필수 전처리\Part 4. 머신러닝을 위한 필수 전처리\데이터")
import numpy as np
import pandas as pddf1 = pd.read_csv("2019년_서울_아파트매매_실거래가.csv", encoding='cp949') # 데이터에 한글이 포함되기 때문에 'cp949'
df2 = pd.read_csv("2019년_서울시_아파트주소.csv", encoding='cp949')df1.head()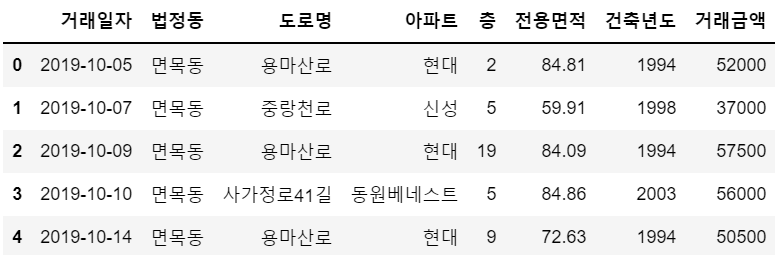
df2.head()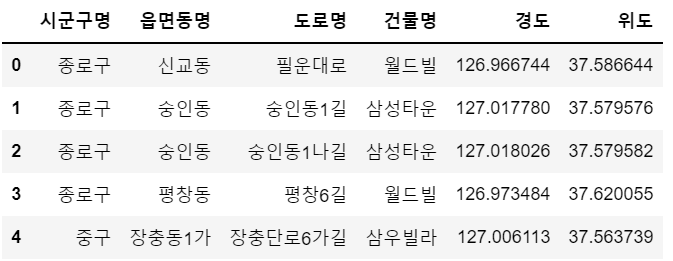
# 데이터 병합(키 변수의 이름이 다르고, 키 변수로 여러개 사용)
df = pd.merge(df1, df2, left_on=['법정동', '도로명', '아파트'], right_on=['읍면동명', '도로명', '건물명'])df3 = pd.read_excel("지하철역_위경도.xlsx")
df3.head()
df는 아파트의 위치(경위도)를 나타내는 데이터프레임 / df3는 지하철의 위치(경위도)를 나타내는 데이터프레임이다.
지금부터는 아파트의 위치로부터 가장 가까운 지하철역과 그 거리를 구해서 데이터프레임을 합치는 작업을 할 것이다.
# 거리 행렬을 만들기 위해 계산 대상인 행렬 만듬
df_location = df[['경도', '위도']]
df3_location = df3[['경도', '위도']]# 거리 행렬 생성
from scipy.spatial.distance import cdist
dist_mat = cdist(XA=df_location, XB=df3_location, metric='cityblock')거리 행렬에서 df_location(아파트)이 행이고 df3_location(지하철)이 열이니까 각각 아파트에 대해서 가장 가까운 지하철역의 위치를 가지고 올려면 axis를 1로 설정하고, [:,0]는 행은 전체, 열은 맨 앞에 나온 값들이 각 아파트 별로 가장 가까운 지하철의 index이다.
close_subway_index = dist_mat.argsort(axis=1)[:, 0]
df['가까운역'] = df3.iloc[close_subway_index]['역명'].values
# df3에서 close_subway_index의 인덱스 값들만 iloc로 가져와서 거기에 해당하는 역명만 가지고옴
# (tip) 새로운 시리즈를 만들 때는 list, ndarray를 사용하는 것이 바람직함
df['가까운역까지_거리'] = dist_mat[close_subway_index][:, 0]df.head()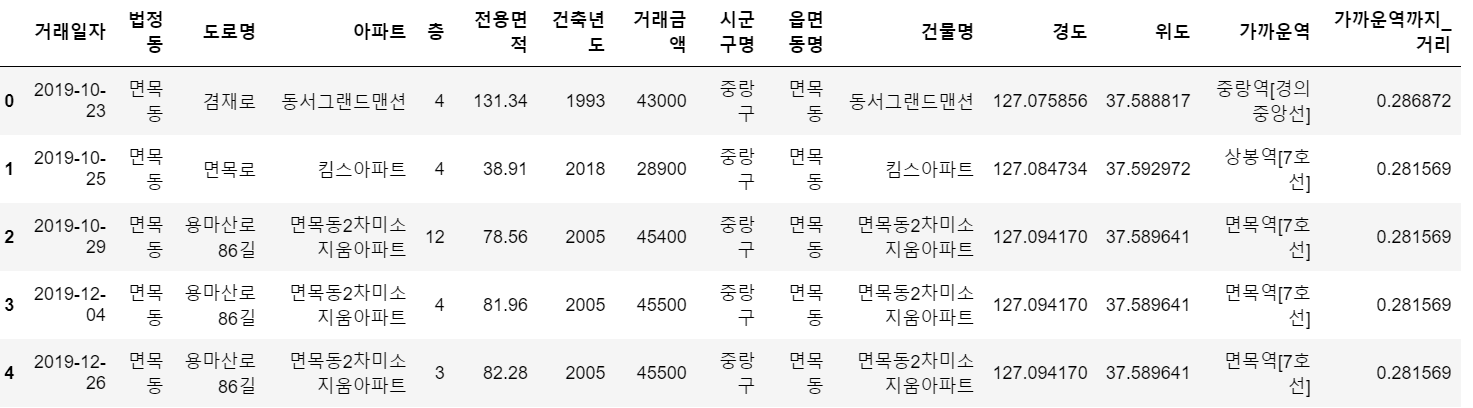
데이터를 병합하는 방식 중 거리 기반 병합이 필요한 경우를 살펴보았다. 이번 시간에 공부한 내용이 데이터 파편화 문제 1, 2, 3에서 공부한 내용보다 다소 생소하고 어렵게 느껴져서 여러번 다시 볼 예정이다.
'데이터 전처리 > 머신러닝을 위한 필수 전처리' 카테고리의 다른 글
| 결측치 문제 (0) | 2022.12.13 |
|---|---|
| 데이터 파편화 문제(5)(데이터 요약이 필요한 경우) (0) | 2022.12.13 |
| 데이터 파편화 문제(3)(포맷이 다른 키 변수가 있는 경우) (0) | 2022.12.12 |
| 데이터 파편화 문제(2)(명시적인 키 변수가 있는 경우) (0) | 2022.12.12 |
| 데이터 파편화 문제(1)(파일이 분산 저장되어 있는 경우) (0) | 2022.12.12 |