파일 자체가 나뉘어 저장된 경우
지도학습 모델을 학습하려면 아래와 같이 반드시 하나의 통합된 데이터 집합이 필요하다. 많은 경우에 데이터가 두 개 이상으로 나뉘어져 있어, 이들을 반드시 통합하는 전처리를 수행해야 한다.

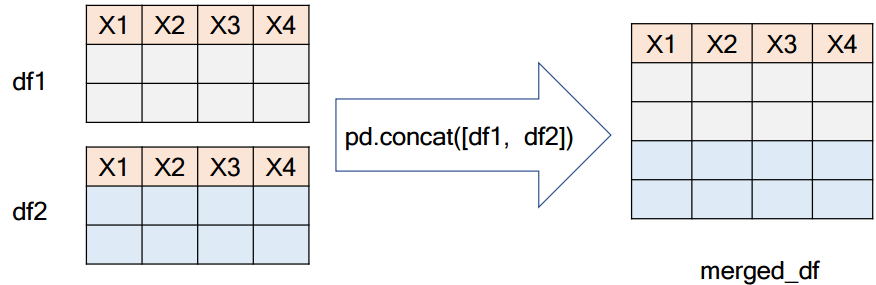
센서, 로그, 거래 데이터 등과 같이 크기가 매우 큰 데이터는 시간과 ID 등에 따라 분할되어 저장된 경우가 존재한다. 이렇게 분할되어 저장된 데이터는 pandas.concat 함수를 사용하면 손쉽게 해결할 수 있다.
만약, 통합해야 하는 데이터가 많은 경우에는 빈 데이터프레임을 생성한 뒤, 이 데이터프레임과 반복문을 사용하여 불러온 데이터를 concat 함수를 이용하면 효율적으로 통합할 수 있다.
◆pandas.concat
둘 이상의 데이터 프레임을 이어 붙이는데 사용하는 함수이다.
-주요 입력
▷objs: DataFrame을 요소로 하는 리스트(입력 예시: [df1, df2])로 입력 순서대로 병합이 된다.
▷ignore_index: True면 기존 인덱스를 무시하고 새로운 인덱스를 부여하며, False면 기존 인덱스를 사용한다.

▷axis가 0이면 행 단위로 병합을 수행하며, 1이면 열 단위로 병합을 수행한다.
(Tip) axis
axis는 numpy 및 pandas의 많은 함수에 사용되는 키워드로, 연산 등을 수행할 때 축의 방향을 결정하는 역할을 한다.
→ axis는 그 함수의 결과 구조가 벡터 형태(1차원)인지, 행렬 형태(2차원)인지에 따라 아래 표와 같이 적용 시키면 된다.

아래 그림의 예를 보자.

왼쪽 결과 구조와 오른쪽 결과 구조가 벡터이기 때문에 각각에 맞는 axis를 설정했다.
오른쪽 결과 구조가 행렬이기 때문에 위의 예는 아래로 결합했으므로 즉, 연산 과정이 행 기준으로 axis=0이다. (axis=0은 default 값)
(Tip) os.listdir
-주요 입력
▷path: 입력된 경로(path) 상에 있는 모든 파일명을 리스트 형태로 반환한다.

## 코드 실습 ##
import os
os.chdir(r"C:\Users\82102\Desktop\데이터전처리\머신러닝을 위한 필수 전처리\Part 4. 머신러닝을 위한 필수 전처리\데이터")
import pandas as pdos.listdir("에너지 사용량 예측")
# 입력된 경로에 5월을 제외한 날짜별 데이터를 결합할 예정
merged_df = pd.DataFrame() # 빈 데이터 프레임 생성
for file in os.listdir("에너지 사용량 예측"): # file이 에너지 사용량 예측 폴더 내에 있는 파일명을 순회
if '5월' not in file and '.csv' in file:
df = pd.read_csv("에너지 사용량 예측/" + file) # 현재 경로는 ../데이터이므로 에너지 사용량 예측 폴더를 명시해줘야 함
merged_df = pd.concat([merged_df, df], axis=0, ignore_index=True) # axis=0 : 날짜별 데이터이므로 행 기준으로 결합# 날짜 기준 정렬 수행
merged_df.sort_values('date', inplace=True)
'데이터 전처리 > 머신러닝을 위한 필수 전처리' 카테고리의 다른 글
| 결측치 문제 (0) | 2022.12.13 |
|---|---|
| 데이터 파편화 문제(5)(데이터 요약이 필요한 경우) (0) | 2022.12.13 |
| 데이터 파편화 문제(4)(거리 기반 병합이 필요한 경우) (0) | 2022.12.13 |
| 데이터 파편화 문제(3)(포맷이 다른 키 변수가 있는 경우) (0) | 2022.12.12 |
| 데이터 파편화 문제(2)(명시적인 키 변수가 있는 경우) (0) | 2022.12.12 |