포맷이 다른 키 변수가 있는 경우
- 참조 데이터가 필요 없는 경우의 병합
시간과 날짜 컬럼 등은 데이터에 따라 포맷이 다른 경우가 잦다. 키 변수의 포맷이 다른 두 DataFrame에 대해 merge를 적용하면, 비정상적으로 병합이 이뤄질 수 있으므로, 하나의 컬럼을 다른 컬럼의 포맷에 맞게 변경해주는 작업이 필요하다.

(Tip) Series.apply
Series에 있는 모든 요소에 func을 일괄 적용하는 함수이다.
-주요 입력
▷func: Series의 요소를 처리하는 함수
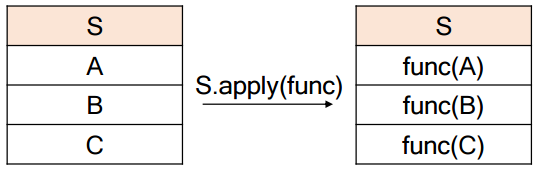
apply 함수는 코드의 효율성을 위해 굉장히 자주 사용된다.
## 코드 실습 ##
import os
os.chdir(r"C:\Users\82102\Desktop\데이터전처리\머신러닝을 위한 필수 전처리\Part 4. 머신러닝을 위한 필수 전처리\데이터")
import pandas as pddf1 = pd.read_csv("날짜포맷이다른데이터1.csv")
df2 = pd.read_csv("날짜포맷이다른데이터2.csv")df1.head(1)
df2.head(1)
# df1의 날짜 타입을 df2의 날짜 타입으로 변경하는 함수 작성 및 적용
def data_type_converter(value):
YYYY, MM, DD = value.split('-')
return YYYY + "년 " + str(int(MM)) + "월 " + str(int(DD)) + "일"
# 한자리 수의 월과 일의 경우 0이 붙기 때문에 int로 변환(01->1, 08->8로 변환)
# str으로 바꿔준 이유는 YYYY년은 str이기 때문에 병합을 위해서 str으로 바꿈
df1['날짜'] = df1['날짜'].apply(data_type_converter)df1.head(1) # df2의 날짜 포맷에 맞게 변경된 것을 확인
# 데이터 병합
merged_df = pd.merge(df1, df2, on='날짜')
- 참조 데이터가 필요한 경우의 병합
도로명 주소↔지번주소, 회원명↔회원번호 등과 같이 일정한 패턴이 없이 포맷이 다른 경우에는 컬럼 값을 참조 데이터를 이용하여 변경해야 한다.
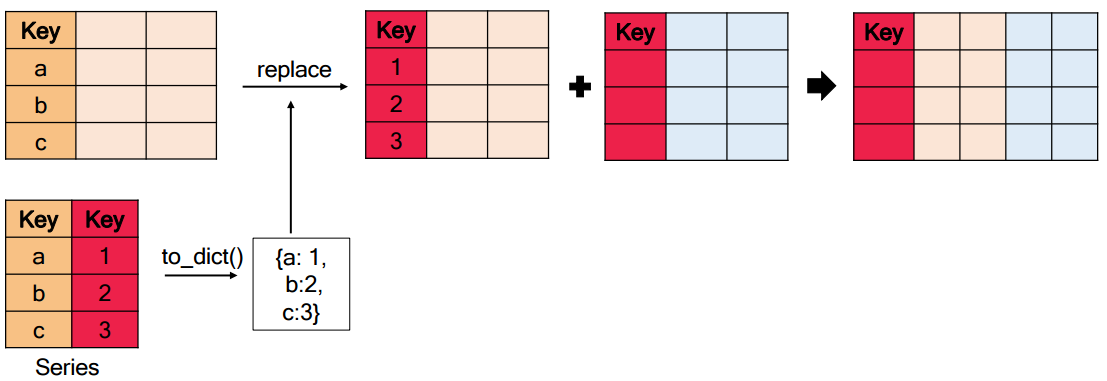
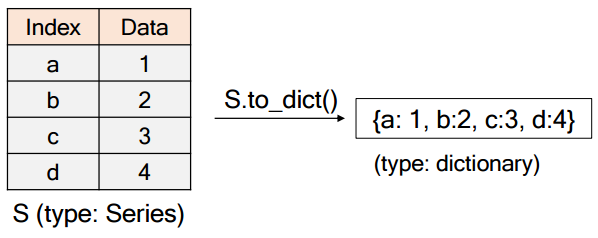
(Tip) Series.to_dict()
Series의 index를 key로, data를 value로 하는 사전으로 변환한다.
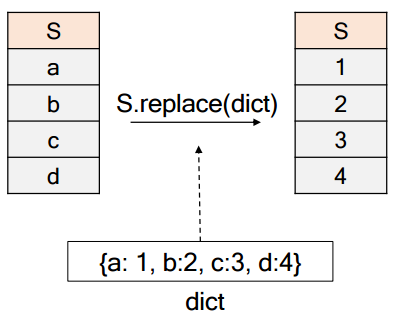
(Tip) Series.replace
dict을 입력 받아, Series 내에 있는 요소 가운데 key와 같은 값을 value로 변환해준다.
## 코드 실습 ##
import os
os.chdir(r"C:\Users\82102\Desktop\데이터전처리\머신러닝을 위한 필수 전처리\Part 4. 머신러닝을 위한 필수 전처리\데이터")
import pandas as pddf1 = pd.read_excel("인구수데이터.xlsx", sheet_name="202006")
df2 = pd.read_excel("인구수데이터.xlsx", sheet_name="201108")
ref_df = pd.read_csv("시승격정보.csv", encoding='cp949') # 참조 데이터# ref_df를 사전으로 변환
ref_dict = ref_df.set_index('승격전')['승격후'].to_dict() # 인덱스 설정 및 시리즈로 변환 후 딕셔너리로 변환# ref_dict를 이용하여 key와 같은 값을 value로 변환
df2['행정구역'] = df2['행정구역'].replace(ref_dict)df1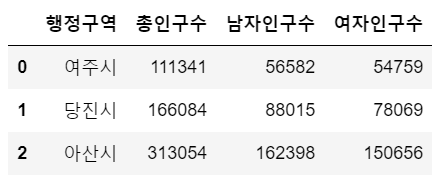
df2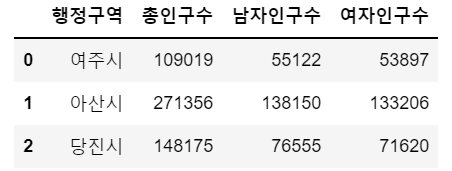
# df1과 df2에 있는 변수명이 모두 같으므로, 해당 변수가 201108인지 202006인지 알기 위해서 변수명을 수정
df1.set_index("행정구역", inplace=True) # 행정구역 변수명은 바꾸지 않기 위해, 인덱스로 설정
df2.set_index("행정구역", inplace=True) # 행정구역 변수명은 바꾸지 않기 위해, 인덱스로 설정
df1 = df1.add_prefix("202006_") # add_prefix는 전체 변수명 앞부분에 공통된 글자나 기호를 붙여줌
df2 = df2.add_prefix("201108")merged_df = pd.merge(df1, df2, left_index=True, right_index=True) # df1, df2의 인덱스를 키 변수로 mergemerged_df
'데이터 전처리 > 머신러닝을 위한 필수 전처리' 카테고리의 다른 글
| 결측치 문제 (0) | 2022.12.13 |
|---|---|
| 데이터 파편화 문제(5)(데이터 요약이 필요한 경우) (0) | 2022.12.13 |
| 데이터 파편화 문제(4)(거리 기반 병합이 필요한 경우) (0) | 2022.12.13 |
| 데이터 파편화 문제(2)(명시적인 키 변수가 있는 경우) (0) | 2022.12.12 |
| 데이터 파편화 문제(1)(파일이 분산 저장되어 있는 경우) (0) | 2022.12.12 |