그리드 서치(하이퍼 파라미터와 하이퍼 파라미터 튜닝)
모델 및 파라미터 선정을 할 때 어떠한 데이터에 대해서도 우수한 모델과 그 하이퍼 파라미터는 절대 존재하지 않고 또한, 분석적인 방법으로 좋은 모델과 하이퍼 파라미터를 선정하는 것도 불가능하다.
머신러닝에서 하이퍼 파라미터란 사용자의 입력값, 혹은 설정 가능한 옵션이라고 볼 수 있다. 모든 데이터와 문제에 대해 가장 좋은 하이퍼 파라미터 값이 있으면 좋겠지만 데이터에 따라 좋은 하이퍼 파라미터라는 것이 다르다. 그래서 데이터마다 좋은 입력값과 모델을 설정해주는 작업이 필요한데, 이를 하이퍼 파라미터 튜닝이라고 한다. 예를 들어, k-최근접 이웃에서 k를 3으로도 해보고, 5로도 해보고, 10으로도 해 본 다음 / 서포트 벡터 머신에서 kernel을 'rbf'로도 해보고, 'linear'로도 해 본 다음 그 가운데 가장 좋은 모델과 그 모델의 하이퍼 파라미터를 찾는 과정이다. 하이퍼 파라미터 튜닝을 노가다라고 표현한 이유는 해보기 전까지 어떤 모델, 어떤 하이퍼 파라미터가 좋을지 알 수 없기 때문이다.
- 그리드 서치 개요
하이퍼 파라미터 그리드는 한 모델의 하이퍼 파라미터 조합을 나타내며, 그리드 서치란 하이퍼 파라미터 그리드에 속한 모든 파라미터 조합을 비교 평가하는 방법을 의미한다.
예시: k-최근접 이웃의 파라미터 그리드
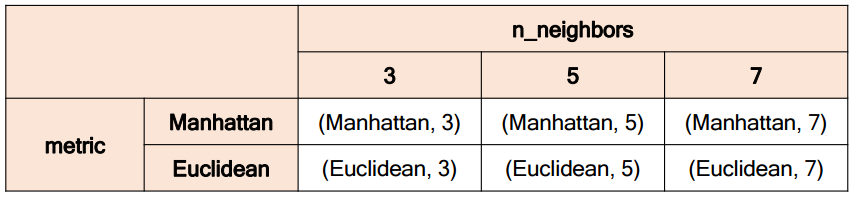
->총 여섯 개의 하이퍼 파라미터 조합에 대한 성능을 평가하여, 그 중 가장 우수한 하이퍼 파라미터를 선택한다.
- 그리드 서치 코드 구현: GridSearchCV
sklearn을 활용하여 그리드 서치를 구현하려면 사전 형태로 하이퍼 파라미터 그리드를 정의해야 한다.
-Key: 하이퍼 파라미터명(str)
-Value: 해당 파라미터의 범위(list)

★sklearn.model_selection.GridSearchCV
▶주요 입력
- estimator: 모델(sklearn 인스턴스)
- param_grid: 파라미터 그리드(사전)
- cv: k겹 교차 검증에서의 k(2 이상의 자연수)
- scoring_func: 평가 함수(sklearn 평가 함수: accuray, f1-score, mae 등)
▶GridSearchCV 인스턴스(GSCV)의 주요 method 및 attribute
- GSCV = GridSearchCV(estimator, param_grid, cv, scoring_func): 인스턴스화
- GSCV.fit(X, Y): 특징 벡터 X와 라벨 Y에 대해 param_grid에 속한 파라미터를 갖는 모델을 k-겹 교차검증 방식으로 평가하여, 그 중 가장 우수한 파라미터를 찾음
-GSCV.get_params(): 가장 우수한 파라미터를 반환
▶GridSearchCV는 사용이 편하다는 장점이 있지만, k-겹 교차검증 방식을 사용하기에 속도가 느리고
모델 성능 향상을 위한 전처리 기법을 적용할 수 없다는 단점이 있다. 그래서 사용하는 것이 ParameterGrid이다.
★sklearn.model_selection.ParameterGrid
▶param_grid(사전 형태의 하이퍼 파라미터 그리드)를 입력 받아, 가능한 모든 파라미터 조합을 사전 형태의 요소로 하는 generator를 반환하는 함수이다.

▶GridSearchCV에 비해 사용이 어렵다는 단점이 있지만,
모델 성능 향상을 위한 전처리 기법을 적용하는데 문제가 없어서 실무에서 훨씬 자주 사용된다.
ParameterGrid 사용을 위해 알아야 하는 문법이 두 가지가 있다.
첫째, 함수의 입력으로 사전 자료형을 사용하는 경우에는 **를 사전 앞에 붙여야 함
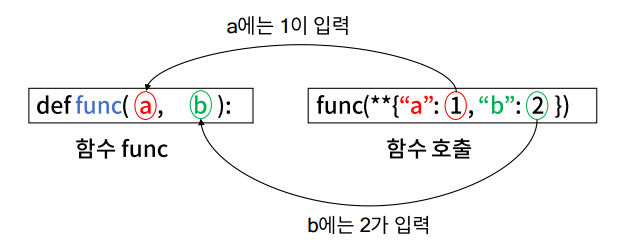
이를 활용하면, ParameterGrid 인스턴스를 순회하는 사전 자료형인 변수(파라미터)를 모델의 입력으로 넣을 수 있다.
둘째, ParameterGrid 인스턴스를 순회하면서 성능이 가장 우수한 값을 찾으려면 최대값(최소값)을 찾는 알고리즘을 알아야 한다.
->분류 모델의 경우 모델 평가지표가 클수록 좋은 모델이기 때문에 최대값을 찾는 것이 목적이고, 예측 모델의 경우 모델 평가지표가 작을수록 좋은 모델이기 때문에 최소값을 찾는 것이 목적이다.
->내장 함수인 max 함수나 min 함수를 사용해도 되지만, 평가해야 하는 하이퍼 파라미터 개수가 많으면 불필요한 메모리 낭비로 이어질 수 있으며, 더욱이 모델도 같이 추가되야 하므로 메로리 에러로 이어지기 쉽기 때문에 최대값(최소값)을 찾는 알고리즘을 알아야 한다.

위 그림을 보면 최대값을 찾기 위해서는 Max_value란 값을 매우 작은 값으로 초기화를 시켜준 뒤 비교를 진행하고 최소값을 찾기 위해서는 Min_value란 값을 매우 큰 값으로 초기화를 시켜준 뒤 비교를 진행한다.
(만약, accuracy의 최대값을 찾는다면 Max_value를 -1로 초기화 하더라도 문제가 없다. 왜냐하면 accuracy는 아무리 작아도 0이기 때문이다.)
위에서 설명한 과정을 코드를 통해 구현을 해볼것이다.
## ParameterGrid
from sklearn.model_selection import ParameterGrid
grid = {'n_neighbors': [3,5,7],
'metric': ['Manhattan','Euclidean']}
list(ParameterGrid(grid))
## 함수의 입력으로 사전을 입력받기: **의 사용
def f(a,b):
return a + b
input_f = {"a":1, "b":2}
f(**input_f)
## 최대값 찾기 알고리즘 예시
L = [10, 20, 30, 10, 20]
max_value = -99999 # 매우 작은 값으로 설정
for value in L:
if max_value < value:
max_value = value # 탐색한 값이 현재 최대값보다 크면 업데이트
print(max_value)
## 최소값 찾기 알고리즘 예시
L = [10, 20, 30, 10, 20]
min_value = 99999 # 매우 큰 값으로 설정
for value in L:
if min_value > value:
min_value = value # 탐색한 값이 현재 최소값보다 작으면 업데이트
print(min_value)
## 그리드 서치 실습(하이퍼 파라미터 튜닝 실습) ##
*사용 데이터: iris dataset
*사용 모델: (1) k-최근접 이웃
- n_neighbors(3, 5, 7)
- metric(euclidean, manhattan)
*사용 모델: (2) 서포트 벡터 머신
- kernel: rbf, linear
- C: 0.1, 1, 10
*평가 척도:f1 score
# iris 데이터 불러오기
from sklearn.datasets import load_iris
X = load_iris()['data'] # feature
Y = load_iris()['target'] # label# 학습 데이터와 평가 데이터 분할
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X, Y, random_state=1004)모델은 KNN과 SVM을 사용한다
# 모델, ParameterGrid 불러오기
from sklearn.model_selection import ParameterGrid
from sklearn.neighbors import KNeighborsClassifier as KNN
from sklearn.svm import SVC모델별 파라미터 그리드를 설계한다.
param_grid_for_knn은 KNN의 파라미터 그리드를, param_grid_for_svm은 SVM의 파라미터 그리드를 정의한다.
그리고 이 값들을 param_grid라는 사전에 추가한다. 이는 모델이 여러 개 있을 때 파라미터 튜닝을 쉽게 하는 방법이다.
# 파라미터 그리드 생성
param_grid = dict()
# 입력: 모델 함수, 출력: 모델의 하이퍼 파라미터 그리드
# 모델별 파라미터 그리드 생성
param_grid_for_knn = ParameterGrid({'n_neighbors': [3,5,7],
'metric': ['euclidean', 'manhattan']})
param_grid_for_svm = ParameterGrid({'C':[0.1,1,10],
'kernel':['rbf','linear']})
# 모델-하이퍼 파라미터 그리드를 param_grid에 추가
param_grid[KNN] = param_grid_for_knn
param_grid[SVC] = param_grid_for_svm밑의 코드는 튜닝을 시작하는 과정이다.
먼저, f1_score는 절대 0보다 작을수 없기에 -1로 초기화한다.
model_func으로 KNN과 SVC 함수를 순회하고, 앞서 정의한 param_grid 사전을 이용하여 각 모델의 파라미터를 param으로 받는다. 이제 param으로 각 파라미터를 돌면서 model_func에 param을 입력하여 모델을 학습하고 f1_score를 계산한다. 이 score가 best_score보다 크다면 최고 모델, 점수, 파라미터를 업데이트한다.
# 하이퍼 파라미터 튜닝
best_score = -1 # 분류모델로 평가 척도로 f1_score 사용-> f1_score는 절대 0보다 작을수 없기에 -1로 설정
# 분류 모델의 경우 모델 평가지표가 클수록 좋은 모델이기 때문에 최대값을 찾는 것이 목적
from sklearn.metrics import f1_score
for model_func in [KNN, SVC]:
for param in param_grid[model_func]:
model = model_func(**param).fit(x_train, y_train)
y_pred = model.predict(x_test)
score = f1_score(y_test, y_pred, average='micro')
# iris 데이터는 클래스가 3개인 다중 클래스 분류 문제이다. 그래서 average가 micro나 macro라는 방식으로 정의 되어야 함
if score > best_score:
# 점수가 지금까지 찾은 최고 점수보다 좋으면 최고 모델, 점수, 파라미터 업데이트
best_model_func = model_func
best_score = score
best_param = param
# best_model = model -> 최고 모델과 우수한 파라미터를 적용한 모델을 바로 쓸 경우 이 코드 사용튜닝 결과는 다음과 같다.
print("모델:", best_model_func)
print("점수:", best_score)
print("파라미터:", best_param)
'데이터 전처리 > 지도학습 주요 모델 및 개념' 카테고리의 다른 글
| 지도학습 모델 및 파라미터 선택(복잡도 하이퍼 파라미터 튜닝) (0) | 2022.12.11 |
|---|---|
| 지도학습 모델 및 파라미터 선택(데이터 크기)(맹신하면 안되고 참고만 하기) (0) | 2022.12.09 |
| 주요 모델의 구조 및 특성(2) (0) | 2022.12.08 |
| 주요 모델의 구조 및 특성(1) (0) | 2022.12.06 |
| 모델 개발 프로세스 (0) | 2022.12.05 |