대표값으로 대체(SimpleImpute)
가장 널리 사용되는 방법이지만, (1) 소수 특징에 결측이 쏠린 경우와 (2) 특징 간 상관성이 큰 경우에는 사용하기 부적절하다.

일반적으로 대표값으로 연속형 변수는 평균, 중위수 등 범주형 변수는 최빈값 등을 주로 사용한다. V1이 범주형 변수이고 최빈값을 뽑아야 되는 상황이라 하면 V1에는 1이라는 값 밖에 없기 때문에 V1의 최빈값은 1이다. 그래서 결측을 전부 1로 대체하면 값이 1 한 개밖에 없는데 1이 실제로 V1을 대표할 수 있는 값인지 모른다. 그리고 1로 다 대체를 하게되면 전부 같은 값을 갖게 되기때문에 변수로서 기능을 상실할 위험이 있다.
→소수 특징에 결측이 쏠린 경우 대표값을 대체하는 것은 문제가 있다.

V1에서 0이 5개 1이 4개 있으니 대표값 0으로 대체, V2에서 0이 4개 1이 5개 있으니 대표값 1로 대체한다. 그런데 V1이 0이면 V2가 1이고, V1이 1이면 V2는 0이라는 관계가 명확히 보인다. 즉, V1+V2=1이라는 명확한 관계가 있는데도 무시하고 V1에 0을 넣고 V2에 1을 넣은 것이다.
→대표값으로 대체하는 경우 특징 간 영향을 무시하기 때문에 특징 간 상관성이 큰 경우에는 부적절하다.
(Tip) sklearn을 이용한 전처리 모델(sklearn을 이용한 모든 전처리에 포함되는 내용이니 중요함)
sklearn을 이용한 대부분의 전처리 모델의 활용 과정의 이해는 매우 중요하며, 특히 평가 데이터는 전처리 모델을 학습하는데 사용하지 않음에 주목해야 한다.

step 1) 전처리 모델을 인스턴스화 시킨다.
인스턴스화 시킨게 Preprocessing model이다.
step 2) Preprocessing model을 Train data를 갖고 fitting을 시킨다.
그러면 Preprocessing model은 Train data를 어떻게 바꿔야 하구나 라는 정보를 기억하게 된다.
예를 들어서 각변수에 결측이 있는데 이 결측값을 뭘로 대체해야 하는지 (각 변수별로 대표값이 어떤건지) 알게 된다.
step 3) 그리고 Preprocessing model을 갖고 transform을 하면 Train data의 결측값들이 모델에 의해 추정된 대표값들로 채워지게 될 것이다. (preprocessed train data 생성)
또는 fit&trainsform을 한꺼번에 하는 함수로 원샷에 처리도 가능하다.
step 4) 그런 다음에 test data를 Preprocessing model로 transform을 해서 preprocessed test data를 생성한다.
또는 데이터를 train&test data를 분할하기전에 전체 데이터에 대해서 Preprocessing model을 갖고 fit&transform을 할수도 있다. 그러나 이런 경우에는 test data를 치팅한 효과가 나타나기 때문에 좋은 방법은 아니다.
주의해야할점은 전처리를 하던 모델링을 하던 우리가 다루는 데이터는 train data에 불과하다.
- 관련 문법: sklearn.impute.SimpleImputer
결측이 있는 변수의 대표값으로 결측을 대체하는 인스턴스이다.
-주요 입력
▷strategy: 대표 통계량을 지정('mean', 'most_frequent', 'median')

변수 타입에 따라 두 개의 인스턴스를 같이 적용해야 할 수 있다. 만약 변수 타입이 혼재가 되어 있을 경우(연속형 변수에 대해서는 mean이나 median을 쓰는게 적합하고, 범주형 변수에 대해서는 most_frequent를 쓰는게 적합)데이터 프레임을 나눈 다음, 각각을 적용시킨후, 다시 열 단위로 이어 붙힌다.
## 코드 실습 ##
- 모든 특징의 타입이 같은 경우
import os
os.chdir(r"C:\Users\82102\Desktop\데이터전처리\머신러닝을 위한 필수 전처리\Part 4. 머신러닝을 위한 필수 전처리\데이터")
import pandas as pddf = pd.read_csv("cleveland.csv")
df.head()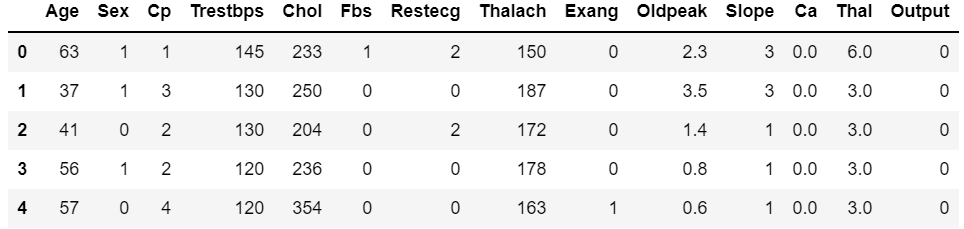
X = df.drop('Output', axis=1)
Y = df['Output']from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X, Y)x_train.isnull().sum(axis=0)
결측치가 많이 없어서 열 단위 결측 삭제 하기에는 적합하지 않지만 행 단위 결측 삭제 하기에는 적합해 보인다.
가정1: 도메인 지식에 의해 새로 들어온 데이터에 결측이 있을 수도 있다고 가정
→가정 1에 의해 학습 데이터에서 결측을 지웠을 때 새로 들어온 데이터도 결측을 지우는 방법이 있지만 결측값을 대표값으로 대체하기로 결정했다.
# 평균 상관계수 확인(주의: 모든 변수가 연속형이므로 가능한 접근)
x_train.corr().sum() / (len(x_train.columns)-1)

열 별 상관계수의 합을 구한뒤 (열 개수 -1)로 나누어준다. 여기서 1을 뺀 이유는 대각행렬의 값은 모두 1이기 때문이다.
(대각행렬을 빼고 평균 상관계수를 구할거면 (x_train.corr().sum()-1) / (len(x_train.columns)-1) 코드, 대각행렬을 포함해서 평균 상관계수를 구할거면 (x_train.corr().sum) / (len(x_train.columns)코드가 맞다고 생각한다.)
→상관계수가 높지 않기 때문에 특징 간 관계가 크지 않다고 판단한다. 그래서 결측을 대표값으로 대체 가능하다고 판단한다.
# 대표값을 활용한 결측치 대체
from sklearn.impute import SimpleImputer
# SimpleImputer 인스턴스화
SI = SimpleImputer(strategy='mean')
# 학습
# fit을 하면 위에 Ca 변수의 대표값과 Thal 변수의 대표값을 계산할 수 있게 된다.
# 엄밀하게는 모든 피쳐에 대해 mean을 계산해서 기억하고 있을 것이다.
SI.fit(x_train)
# sklearn instance의 출력은 ndarray이므로 다시 DataFrame으로 바꿔줌
x_train = pd.DataFrame(SI.transform(x_train), columns=x_train.columns)
x_test = pd.DataFrame(SI.transform(x_test), columns=x_test.columns)x_train.isnull().sum(axis=0)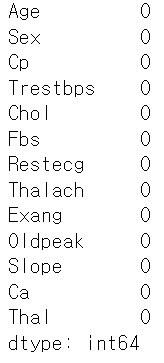
- 다른 타입의 특징이 있는 경우
df = pd.read_csv("saheart.csv")
df.head()
X = df.drop('Chd', axis=1)
Y = df['Chd']from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X, Y)x_train.isnull().sum(axis=0)
# 결측치가 많지 않음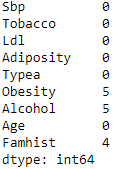
결측치가 많이 없어서 열 단위 결측 삭제 하기에는 적합하지 않지만 행 단위 결측 삭제 하기에는 적합해 보인다.
가정1: 도메인 지식에 의해 새로 들어온 데이터에 결측이 있을 수도 있다고 가정
→가정 1에 의해 학습 데이터에서 결측을 지웠을 때 새로 들어온 데이터도 결측을 지우는 방법이 있지만 결측값을 대표값으로 대체하기로 결정했다.
# 평균 상관 계수 확인 (주의: 모든 변수가 연속형이므로 가능한 접근)
x_train.corr().sum() / (len(x_train.columns)-1)
Adipostiy 변수의 상관계수가 높지만 실습을 위해서 높지 않다고 가정하고 진행한다. 사실 엄밀하게 따지면 위에서 나온 상관계수는 틀린것이다. 데이터가 연속형과 범주형이 섞여있기 때문에 통계분석(범주형일 경우 Anova 검정을 하거나 연속형일 경우 피어슨 상관계수를 구한다던가 하는 방식)으로 이 변수들간에 관계성을 구해야 하는게 맞다.
"saheart.csv" 데이터 설명서를 보면 'Famhist'는 범주형 변수이고 나머지는 연속형 변수이다.
그래서 대표값을 평균을 사용할지, 최빈값을 사용할지 결정이 어렵기 때문에 결론은 변수의 형태에 따라 데이터를 분할해서 각각에 맞는 SimpleImputer를 진행해야 한다.
따라서 데이터를 아래와 같이 분할한다.
x_train_cate = x_train[['Famhist']] # 학습 데이터(범주형 변수)
x_train_cont = x_train.drop('Famhist', axis=1) # 학습 데이터(연속형 변수)
x_test_cate = x_test[['Famhist']] # 평가 데이터(범주형 변수)
x_test_cont = x_test.drop('Famhist', axis=1) # 평가 데이터(연속형 변수)
그후, SimpleImputer를 이용한 대표값을 활용한 결측치 대체한다.
# 대표값을 활용한 결측치 대체
from sklearn.impute import SimpleImputer
# SimpleImputer 인스턴스화
SI_mode = SimpleImputer(strategy='most_frequent')
SI_mean = SimpleImputer(strategy='mean')
# 학습
SI_mode.fit(x_train_cate)
SI_mean.fit(x_train_cont)
# sklearn instance의 출력은 ndarray이므로 다시 DataFrame으로 바꿔줌
x_train_cate = pd.DataFrame(SI_mode.transform(x_train_cate),
columns=x_train_cate.columns)
x_test_cate = pd.DataFrame(SI_mode.transform(x_test_cate),
columns=x_test_cate.columns)
x_train_cont = pd.DataFrame(SI_mean.transform(x_train_cont),
columns=x_train_cont.columns)
x_test_cont = pd.DataFrame(SI_mean.transform(x_test_cont),
columns=x_test_cont.columns)
# 두 데이터를 열단위로 이어붙힘
# 컬럼명이 있어야 하기 때문에 default값인 ignore_index=False 사용(default 값이니 명시는 안해줌)
x_train = pd.concat([x_train_cate, x_train_cont], axis=1)
x_test = pd.concat([x_test_cate, x_test_cont], axis=1)x_train.isnull().sum(axis=0)
(Tip) 이진형 변수와 연속형 변수만 포함된 경우에는 SI_mean만 사용하여 결측치를 평균으로 대체한 뒤에, 이진형 변수에 대해서만 round(반올림) 처리를 하면 하나의 인스턴스만 활용할 수 있다.
즉, 이진형 변수는 mean을 쓴다음에 거기에 round 처리를 해줘야 한다. 왜냐하면 이진형 변수의 평균이 결국에는 1의 비율과 같기 때문이다. 만약에 평균을 구했을때 0.4이면 0 이 더 많다는 소리이고, 0.7이다라고 하면 1이 더 많다는 얘기이다. 그러면 그 값을 바탕으로 round 시켜주면 0.5 이상이면 1로 바뀔테고 0.5미만이면 0으로 바뀔것이다.
이렇듯 위와 같이 범주형, 연속형 처럼 따로 전처리 모델을 학습할 필요가 없다.
'데이터 전처리 > 머신러닝을 위한 필수 전처리' 카테고리의 다른 글
| 결측치 문제 해결 방법(4) 결측치 예측 모델 활용(KNNImputer) (0) | 2022.12.19 |
|---|---|
| 결측치 문제 해결 방법(3) 근처값으로 대체(시계열 변수 한정) (0) | 2022.12.19 |
| 결측치 문제 해결 방법(1) 삭제 (0) | 2022.12.14 |
| 결측치 문제 (0) | 2022.12.13 |
| 데이터 파편화 문제(5)(데이터 요약이 필요한 경우) (0) | 2022.12.13 |