LightGBM
LightGBM은 XGBoost와 함께 부스팅 계열 알고리즘에서 가장 각광을 받고 있다. LightGBM과 XGBoost의 예측 성능은 별다른 차이가 없지만 LightGBM이 XGBoost보다 2년 후에 만들어지다 보니 XGBoost의 장점은 계승하고 단점은 보완하는 방식으로 개발됐다. 또한 기능상의 다양성은 LightGBM이 약간 더 많다.
XGBoost와 마찬가지로, 대용량 데이터에 대한 뛰어난 예측 성능 및 병렬 컴퓨팅 기능을 제공하며, 최근에는 GPU까지 지원하고 있다.
<LightGBM의 XGBoost 대비 장점>
●더 빠른 학습과 예측 수행 시간
●더 작은 메모리 사용량
●카테고리형 피처의 자동 변환과 최적 분할(원-핫 인코딩등을 사용하지 않고도 카테고리형 피처를 자동으로 변환하고 이에 따른 최적의 노드 분할 수행)
<LightGBM의 트리 분할 방식 - 리프 중심 트리 분할>
기존의 대부분 트리 기반 알고리즘은 tree를 수평으로 확장(level-wise)하는 반명 LightGBM은 tree를 수직으로 확장(leaf-wise)
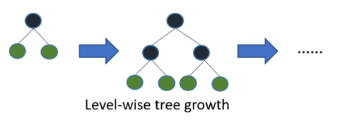
●Level-wise tree growth(수평 확장, 균형 트리 분할)
최대한 균형 잡힌 트리를 유지하면서 분할하기 때문에 트리의 깊이가 최소화되어 overfitting에 강한 구조이다.
하지만 균형을 맞추기 위한 시간이 필요
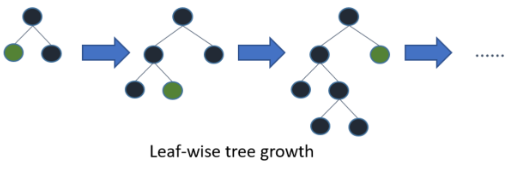
●Leaf-wise tree growth(수직 확장, 리프 중심 트리 분할)
트리의 균형을 맞추지 않고, 최대 손실 값(max delta loss)을 가지는 리프 노드를 지속적으로 분할하면서 트리의 깊이가 깊어지고 비대칭적인 트리가 생성된다. 이렇게 생성된 트리는 학습을 반복할수록 결국은 균형 트리 분할 방식보다 예측 오류 손실을 최소화할 수 있다.
즉, 트리의 어느 레벨에서 모든 노드를 확장시키는 것이 아닌 최종 노드 하나만 분할하는 방식을 사용
loss가 가장 큰 부분을 쪼개고 쪼개서 결국 최대한으로 줄여지는 것이 가능
다른 노드들을 분할시키지 않고 오로지 residual이 큰 노드만 쪼개다보니 메모리의 절약과 속도를 향상시킬 수 있음
<LightGBM 파이썬 구현>
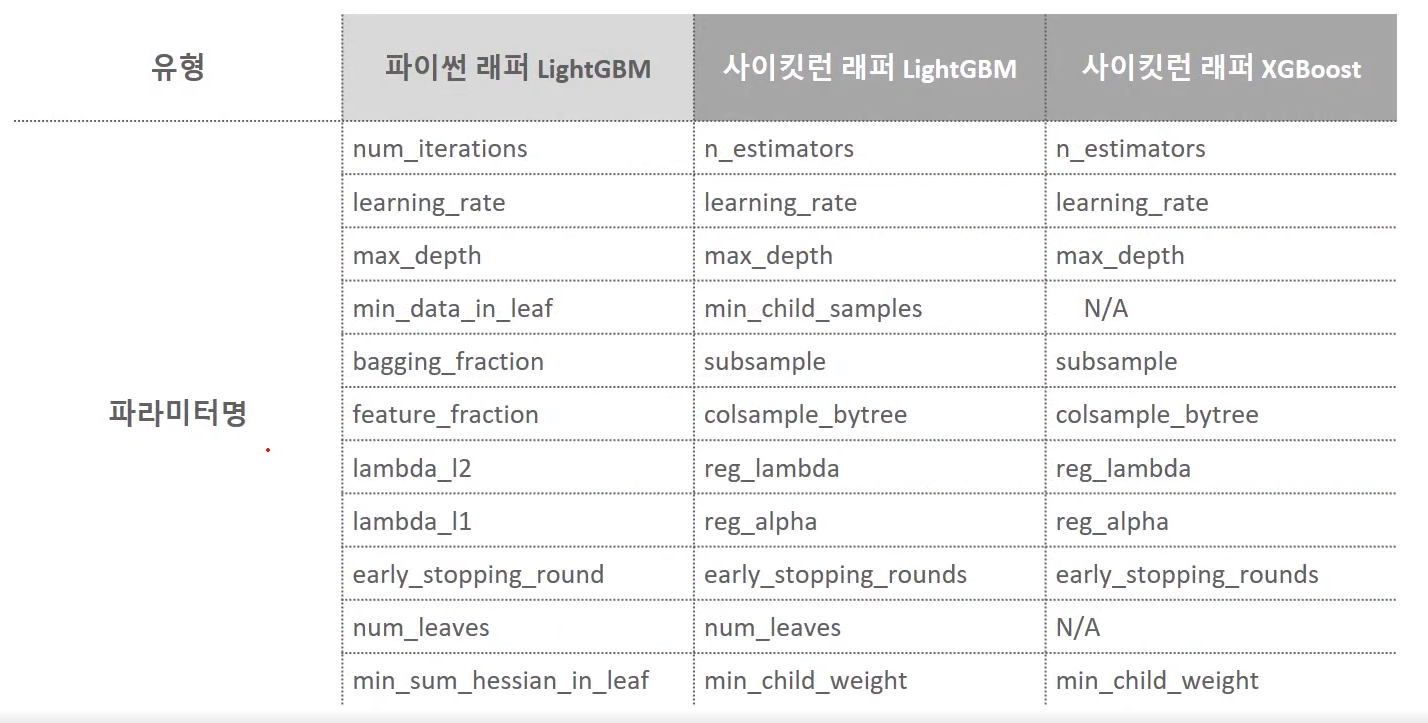
XGBoost와 마찬가지로 파이썬 래퍼, 사이킷런 래퍼로 구분됨

<LightGBM 하이퍼 파라미터>
LightGBM 하이퍼 파라미터는 XGBoost와 많은 부분 유사하지만, LightGBM은 XGBoost와 다르게 리프 노드가 계속 분할되면서 트리의 깊이가 깊어지므로 이러한 트리 특성에 맞는 하이퍼 파라미터 설정이 필요

하이퍼 파라미터 튜닝 방안
num_leaves의 개수를 중심으로 min_child_samples, max_depth를 함께 조정하면서 모델의 복잡도를 줄이는 것이 기본 튜닝 방안임
●num_leaves는 LightGBM 모델의 복잡도를 제어하는 주요 파라미터로 일반적으로 num_leaves의 개수를 높이면 정확도가 높아지지만, 반대로 트리의 깊이가 깊어지고 모델의 복잡도가 커져 과적합 영향도가 커짐
●min_child_samples는 과적합을 개선하기 위한 중요한 파라미터로 num_leaves와 학습 데이터의 크기에 따라 달라지지만, 보통 큰 값으로 설정하면 트리가 깊어지는 것을 방지
●max_depth는 num_leaves, min_child_samples와 결합해 과적합을 개선하는 데 사용
또한 learning_rate를 작게 하면서 n_estimators를 크게 하는 것은 부스팅 계열 튜닝에서 가장 기본적인 튜닝 방안이므로 이를 적용하는 것도 좋음. 물론 n_estimators를 너무 크게 하는 것은 과적합으로 오히려 성능이 저하될 수 있음에 유념
이 밖에 과적합을 제어하기 위해서 reg_lambda, reg_alpha와 같은 regularization을 적용하거나 학습 데이터에 사용할 피처의 개수나 데이터 샘플링 레코드 개수를 줄이기 위해 colsample_bytree, subsample 파라미터를 적용할 수 있다.
LightGBM 실습 - 위스콘신 유방암 예측
from lightgbm import LGBMClassifier
import pandas as pd
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
dataset = load_breast_cancer()
cancer_df = pd.DataFrame(data=dataset.data, columns=dataset.feature_names)
cancer_df['target'] = dataset.target
X_features = cancer_df.iloc[:, :-1]
y_label = cancer_df.iloc[:, -1]
# 전체 데이터 중 80%는 학습용 데이터, 20%는 테스트용 데이터 추출
X_train, X_test, y_train, y_test = train_test_split(X_features, y_label, test_size=0.2, random_state=156)
# 위에서 만든 X_train, y_train을 다시 쪼개서 90%는 학습, 10%는 검증용 데이터로 분리
X_tr, X_val, y_tr, y_val = train_test_split(X_train, y_train, test_size=0.1, random_state=156)
lgbm_wrapper = LGBMClassifier(n_estimators=400, learning_rate=0.05)
# 조기 중단 수행
evals = [(X_tr, y_tr), (X_val, y_val)]
lgbm_wrapper.fit(X_tr, y_tr, early_stopping_rounds=50, eval_metric='logloss',
eval_set=evals)
preds = lgbm_wrapper.predict(X_test)
pred_proba = lgbm_wrapper.predict_proba(X_test)[:, 1][1] training's binary_logloss: 0.625671 valid_1's binary_logloss: 0.628248
[2] training's binary_logloss: 0.588173 valid_1's binary_logloss: 0.601106
[3] training's binary_logloss: 0.554518 valid_1's binary_logloss: 0.577587
... ... ...
[60] training's binary_logloss: 0.0550801 valid_1's binary_logloss: 0.260746
[61] training's binary_logloss: 0.0532381 valid_1's binary_logloss: 0.260236
[62] training's binary_logloss: 0.0514074 valid_1's binary_logloss: 0.261586
... ... ...
[109] training's binary_logloss: 0.00915965 valid_1's binary_logloss: 0.280752
[110] training's binary_logloss: 0.00882581 valid_1's binary_logloss: 0.282152
[111] training's binary_logloss: 0.00850714 valid_1's binary_logloss: 0.280894조기 중단으로 111번째 반복까지만 수행된 후 학습이 종료했다. 111번째 반복의 logloss가 0.280894, 61번째 반복의 logloss가 0.260236으로서 50번 반복하는 동안 성능 평가 지수가 향상되지 못해서 더 이상 수행하지 않고 학습이 종료됐다. 이렇게 학습된 모델로 예측 성능을 평가해 보자.
from sklearn.metrics import *
def get_clf_eval(y_test, pred=None, pred_proba=None):
confusion = confusion_matrix(y_test, pred)
accuracy = accuracy_score(y_test, pred)
precision = precision_score(y_test, pred)
recall = recall_score(y_test, pred)
f1 = f1_score(y_test, pred)
roc_auc = roc_auc_score(y_test, pred_proba)
print('오차 행렬')
print(confusion)
print('정확도:{0:.4f}, 정밀도:{1:.4f}, 재현율:{2:.4f}, \
F1:{3:.4f}, AUC:{4:.4f}'.format(accuracy, precision, recall, f1, roc_auc))get_clf_eval(y_test, preds, pred_proba)
이렇게 학습된 모델로 예측한 결과 정확도는 95.61%이다.
마찬가지로, LightGBM은 XGBoost와 동일하게 plot_importance()를 통해 피처 중요도를 시각화할 수 있다.
from lightgbm import plot_importance
import matplotlib.pyplot as plt
%matplotlib inline
fig, ax = plt.subplots(figsize=(10,12))
plot_importance(lgbm_wrapper, ax=ax)