인코딩, 스케일링, 로그변환 익히기
데이터 전처리
범주형 변수를 처리하는 데이터 인코딩, 서로 다른 변수의 값 범위를 일정한 수준으로 맞추는 작업인 스케일링에 대해 알아본다. 더 다양하고 구체적인 데이터 전처리는 '데이터 전처리' 카테고리를 참고한다.
데이터 인코딩
사이킷런의 머신러닝 알고리즘은 문자열 값을 입력값으로 허용하지 않는다. 그래서 모든 문자열 값은 인코딩돼서 숫자 형으로 변환해야 한다. 여기서 문자열 피처는 범주형 변수, 코드화된 범주형 변수를 의미한다.
1) 레이블 인코딩(Label encoding)
from sklearn.preprocessing import LabelEncoder
items = ['TV', '냉장고', '전자레인지', '컴퓨터', '선풍기', '선풍기', '믹서', '믹서']
# LabelEncoder를 객체로 생성한 후, fit()과 transform()으로 레이블 인코딩 수행
encoder = LabelEncoder()
encoder.fit(items)
labels = encoder.transform(items)
print('인코딩 변환값:', labels)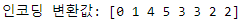
# 문자열 값이 어떤 숫자 값으로 인코딩됐는지 확인 -> LabelEncoder 객체의 classes_
print('인코딩 클래스:', encoder.classes_)
# TV:0, 냉장고:1, 믹서:2, 선풍기:3, 전자레인지:4, 컴퓨터:5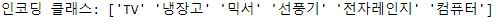
# 인코딩된 값을 다시 디코딩 -> LabelEncoder 객체의 inverse_transform()
print('디코딩 원본값:', encoder.inverse_transform([4, 5, 2, 0, 1, 1, 3, 3]))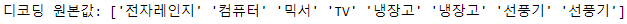
레이블 인코딩은 간단하게 문자열 값을 숫자형 값으로 변환하지만 숫자 값의 대소관계가 작용하기 때문에 몇몇 ML 알고리즘에서 예측 성능이 떨어지는 경우가 발생할 수 있다.
예를들어 냉장고가 1, 믹서가 2로 변환되면, 1보다 2가 더 큰 값이므로 특정 ML 알고리즘에서 가중치가 더 부여되거나 더 중요하게 인식할 가능성이 발생한다. 하지만 냉장고와 믹서의 숫자 변환 값은 단순 코드이지 숫자 값에 따른 순서나 중요도로 인식돼서는 안된다.
이러한 특성 때문에 레이블 인코딩은 선형회귀와 같은 ML 알고리즘에는 적용X, 트리 계열의 ML 알고리즘은 숫자의 이러한 특성을 반영하지 않으므로 레이블 인코딩도 별문제가 없음
→레이블 인코딩의 이러한 문제점을 해결하기 위한 인코딩 방식이 "원-핫 인코딩"
2) 원-핫 인코딩(One-Hot Encoding)
원-핫 인코딩은 피처 값의 유형에 따라 새로운 피처를 추가해 고유 값에 해당하는 컬럼에만 1을 표시하고 나머지 컬럼에는 0을 표시하는 방식
●주의점: 입력값으로 2차원 데이터가 필요, OneHotEncoder를 이용해 변환한 값이 희소행렬(sparse matrix) 형태이므로 이를 다시 toarray() 메서드를 이용해 밀집행렬(dense matrix)로 변환해야 함
from sklearn.preprocessing import OneHotEncoder
import numpy as np
items = ['TV', '냉장고', '전자레인지', '컴퓨터', '선풍기', '선풍기', '믹서', '믹서']
# 2차원 ndarray로 변환
items = np.array(items).reshape(-1,1)
# OneHotEncoder를 객체로 생성한 후, fit()과 transform()으로 원-핫 인코딩 수행
oh_encoder = OneHotEncoder()
oh_encoder.fit(items)
oh_labels = oh_encoder.transform(items)
# OneHotEncoder로 변환한 결과는 희소행렬이므로 toarray()를 이용해 밀집행렬로 변환
print('원-핫 인코딩 데이터')
print(oh_labels.toarray())
print('원-핫 인코딩 데이터 차원')
print(oh_labels.shape)
판다스에는 원-핫 인코딩을 더 쉽게 지원하는 get_dummies()가 있음
import pandas as pd
df = pd.DataFrame({'items':['TV', '냉장고', '전자레인지', '컴퓨터', '선풍기', '선풍기', '믹서', '믹서']})
pd.get_dummies(df)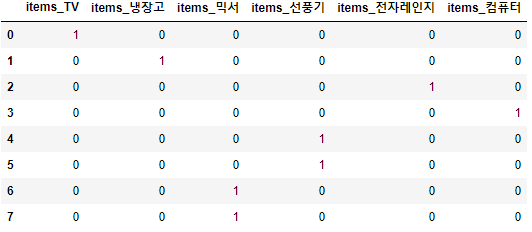
스케일링
스케일링은 서로 다른 피처의 값 범위를 일정한 수준으로 맞추는 작업으로 대표적인 방법인 표준화, 정규화가 있음
●표준화(Standardization)
표준화는 데이터의 피처 각각이 평균이 0이고 분산이 1인 가우시안 정규분포를 가진 값으로 변환하는 것

●정규화(Normalization)
정규화는 서로 다른 피처의 크기를 통일하기 위해 크기를 모두 최소 0 ~ 최대 1의 값으로 변환하는 것

사이킷런에서 제공하는 스케일링 클래스인 StandardScaler, MinMaxScaler를 알아보자!
1) StandardScaler
표준화를 쉽게 지원하는 클래스로, 개별 피처를 평균이 0이고, 분산이 1인 가우시안 정규분포를 가진 값으로 변환
(Scaler 클래스의 fit(), transform()은 2차원 이상 데이터만 가능하다!!)
from sklearn.datasets import load_iris
import pandas as pd
# 붓꽃 데이터 세트를 로딩
iris = load_iris()
iris_df = pd.DataFrame(iris.data, columns=iris.feature_names)
print('feature들의 평균값')
print(iris_df.mean())
print('\nfeature들의 분산값')
print(iris_df.var())
from sklearn.preprocessing import StandardScaler
# StandardScaler 객체 생성
scaler = StandardScaler()
# StandardScaler로 데이터 세트 변환. fit()과 transform() 호출
scaler.fit(iris_df)
iris_scaled = scaler.transform(iris_df)
# transform()시 스케일 변환된 데이터 세트가 ndarray로 반환돼 이를 DataFrame으로 변환
iris_df_scaled = pd.DataFrame(iris_scaled, columns=iris.feature_names)
print('feature들의 평균값')
print(iris_df_scaled.mean())
print('\nfeature들의 분산값')
print(iris_df_scaled.var())
2) MinMaxScaler
정규화를 쉽게 지원하는 클래스로, 서로 다른 피처의 크기를 통일하기 위해 데이터값을 0과 1 사이의 범위 값으로 변환(음수 값이 있으면 -1에서 1값으로 변환)
(Scaler 클래스의 fit(), transform()은 2차원 이상 데이터만 가능하다!!)
from sklearn.preprocessing import MinMaxScaler
# MinMaxScaler 객체 생성
scaler = MinMaxScaler()
# MinMaxScaler로 데이터 세트 변환. fit()과 transform() 호출
scaler.fit(iris_df)
iris_scaled = scaler.transform(iris_df)
# transform()시 스케일 변환된 데이터 세트가 ndarray로 반환돼 이를 DataFrame으로 변환
iris_df_scaled = pd.DataFrame(iris_scaled, columns=iris.feature_names)
print('feature들의 최솟값')
print(iris_df_scaled.min())
print('\nfeautre들의 최댓값')
print(iris_df_scaled.max())
참고로 MinMaxScaler 객체에서 feature_range 인자를 활용해 데이터값의 범위를 조정할 수 있음
★학습 데이터와 테스트 데이터의 스케일링 변환 시 유의점★
fit()은 데이터 변환을 위한 기준 정보를 기억하고 transform()은 이렇게 설정된 정보를 이용해 데이터를 변환함
그런데 학습 데이터 세트와 테스트 데이터 세트에 이 fit()과 transfrom()을 적용할 때 주의가 필요하다.
→다른 전처리 객체도 마찬가지임!!!(SimpleImputer, KNNImputer 등등)
Scaler 객체를 이용해 학습 데이터 세트로 fit()과 transform()을 적용하면 테스트 데이터 세트로는 다시 fit()을 수행하지 않고 학습 데이터 세트로 fit()을 수행한 결과를 이용해 transform() 변환을 적용해야 한다.
즉, 학습 데이터로 fit()이 적용된 스케일링 기준 정보를 그대로 테스트 데이터에 적용해야 하며, 그렇지 않고 테스트 데이터로 다시 새로운 스케일링 기준 정보를 만들게 되면 학습 데이터와 테스트 데이터의 스케일링 기준 정보가 서로 달라지기 때문에 올바른 예측 결과를 도출하지 못한다.
아래 예시를 통해 테스트 데이터에 fit()을 적용할 때 어떠한 문제가 발생하는지 알아보자~
from sklearn.preprocessing import MinMaxScaler
import numpy as np
# 학습 데이터는 0부터 10까지, 테스트 데이터는 0부터 5까지 값을 가지는 데이터 세트로 생성
# Scaler 클래스의 fit(), transform()은 2차원 이상 데이터만 가능하므로 reshape(-1,1)로 차원 변경
train_array = np.arange(0,11).reshape(-1,1)
test_array = np.arange(0,6).reshape(-1,1)# MinMaxScaler를 이용해 학습 데이터 변환
scaler = MinMaxScaler() # MinMaxScaler 객체에 별도의 feature_range 파라미터 값을 지정하지 않으면 0~1 값으로 변환
scaler.fit(train_array)
train_scaled = scaler.transform(train_array)
print('원본 train_array 데이터:', np.round(train_array.reshape(-1), 2))
print('Scale된 train_array 데이터:', np.round(train_scaled.reshape(-1), 2))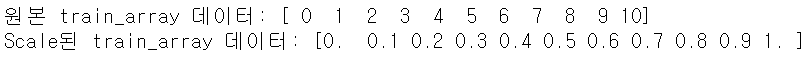
# MinMaxScaler를 이용해 테스트 데이터 변환
scaler.fit(test_array)
test_scaled = scaler.transform(test_array)
print('원본 test_array 데이터:', np.round(test_array.reshape(-1), 2))
print('Scale된 test_array 데이터:', np.round(test_scaled.reshape(-1), 2))
출력 결과를 확인하면 학습 데이터와 테스트 데이터의 스케일링이 맞지 않음을 알 수 있다. 테스트 데이터의 경우 최솟값 0, 최댓값 5이므로 1/5로 스케일링된다. 따라서 원본값 1은 0.2로 원본값 5는 1로 변환이 된다. 앞서 학습 데이터는 스케일링 변환으로 원본값 2가 0.2로 원본값 10이 1로 변환됐다.
→머신러닝 모델은 학습 데이터를 기반으로 학습되기 때문에 반드시 테스트 데이터는 학습 데이터의 스케일링 기준에 따라야 하며, 테스트 데이터의 1 값은 학습 데이터와 동일하게 0.1 값으로 변환돼야 한다. 따라서 테스트 데이터에 다시 fit()을 적용해서는 안되며 학습 데이터로 이미 fit()이 적용된 Scaler 객체를 이용해 transform()으로 변환해야 한다.
다음은 맞는 방법인 테스트 데이터에 fit()을 호출하지 않고 학습 데이터로 fit()을 수행한 MinMaxScaler 객체의 transform()을 이용해 데이터를 변환해보자
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(train_array)
train_scaled = scaler.transform(train_array)
test_scaled = scaler.transform(test_array)
print('원본 train_array 데이터:', np.round(train_array.reshape(-1), 2))
print('Scale된 train_array 데이터:', np.round(train_scaled.reshape(-1), 2))
print('\n원본 test_array 데이터:', np.round(test_array.reshape(-1), 2))
print('Scale된 test_array 데이터:', np.round(test_scaled.reshape(-1), 2))
스케일링 변환 시 유의할 점을 요약하면
첫째, 가능하다면 전체 데이터의 스케일링 변환을 적용한 뒤 학습과 테스트 데이터로 분리
둘째, 1이 여의치 않다면 테스트 데이터 변환 시에는 fit()을 적용하지 않고 학습 데이터로 이미 fit()된 Scaler 객체를 이용해 transform()으로 변환
전처리와 데이터 분할 - 인프런 | 질문 & 답변
선생님, 안녕하세요. 스케일링 파트를 보다가 의문점이 생겨서 문의 드렸습니다. 가능하다면 전체 데이터의 스케일링 변환을 적용한 뒤 학습/테스트 데이터로 분리 하라고 하셨는데 스케일링
www.inflearn.com
로그변환
●log변환은 왜곡된 분포를 가진 피처를 비교적 정규분포에 가깝게 변환 → 변수 치우침을 해결하는 대표적인 처리 방법
●log변환은 로그를 취하는 순간 그 수는 진수가 되어버리니 값이 작아지기 때문에 큰 수치를 같은 비율의 작은 수치로 변환하기 때문에 데이터 분포도의 왜곡을 상당 수준 개선
●넘파이의 log1p() 함수를 이용하여 적용이 가능
로그변환과 스케일링의 차이
딱 정해서 말씀드리면, 개별 feature, 또는 target의 분포도가 skew가 심하면 log 변환을 합니다. Standard Scaler는 일반적으로 선형기반의 머신러닝의 입력 (전체) 데이터들에 대해서 다 적용합니다. 보통 scaling은 전체 feature들에(카테고리성 피처 제외) 다 적용합니다.
Skew가 심하면 로그 변환, 전체 데이터의 스케일링을 표준 정규 분포 형태로 맞추고 싶다면 Standard Scaler를 적용합니다(선형 기반의 머신러닝의 입력에서 MinMax나 Standard scaler를 선호는 합니다)