데이터 전처리/머신러닝 모델의 성능 향상을 위한 전처리
변수 분포 문제-변수 치우침 제거
97dingdong
2022. 12. 26. 17:14
변수 치우침 문제
모델링에 가장 적합한 확률 분포는 정규 분포이나, 실제로 많은 변수가 특정 방향으로 치우쳐 있다.
한 쪽으로 치우친 변수에서 치우친 반대 방향의 값(꼬리 부분)들이 이상치처럼 작용할 수 있으므로, 이러한 치우침을 제거해야 한다.
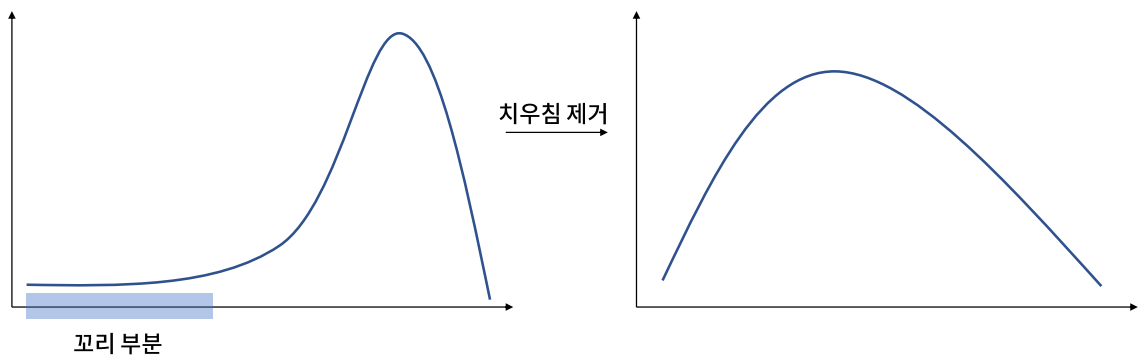
변수 치우침 확인 방법: 왜도(skewness)
변수 치우침을 확인하기 가장 적절한 척도로는 왜도(skewness)가 있다. 왜도는 분포의 비대칭도를 나타내는 통계량으로, 왜도 값에 따른 분포는 다음과 같다.

일반적으로 왜도의 절대값이 1.5이상이면 치우쳤다고 판단한다.
- 관련 문법: scipy.stats
다양한 확률 통계 관련 함수를 제공하는 모듈이다.
- scipy.stats.skew: 왜도를 구하는 함수
- scipy.stats.mode: 최빈값을 구하는 함수
- scipy.stats.kurtosis: 첨도를 구하는 함수
변수 치우침 해결 방법
변수 치우침을 해결하는 기본 아이디어는 값 간 차이를 줄이는데 있다. 대표적인 처리 방법은 다음과 같다.

## 코드 실습 ##
import os
os.chdir(r"C:\Users\82102\Desktop\데이터전처리\머신러닝 모델의 성능 향상을 위한 전처리\5. 머신러닝 모델의 성능 향상을 위한 전처리\데이터")
import pandas as pddf = pd.read_csv("Sonar_Mines_Rocks.csv")
df.head()
# 특징과 라벨 분리
X = df.drop('Y', axis=1)
Y = df['Y']# 학습 데이터와 평가 데이터 분리
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X, Y)# 왜도 확인
x_train.skew() # Band4의 왜도가 가장 크다 -> 어떻게 생겼는지 그래프를 그려보자Band1 2.138244
Band2 2.262066
Band3 2.676642
Band4 3.463153
Band5 2.109983
Band6 1.402875
Band7 1.022341
Band8 1.223893
Band9 1.609178
Band10 1.337977
Band11 0.944374
Band12 0.611857
Band13 0.817726
Band14 1.153231
Band15 0.849569
Band16 0.721450
Band17 0.652667
Band18 0.540473
Band19 0.321763
Band20 0.014367
Band21 -0.169245
Band22 -0.394846
Band23 -0.530914
Band24 -0.680878
Band25 -0.764100
Band26 -0.654374
Band27 -0.592475
Band28 -0.703936
Band29 -0.404197
Band30 -0.177567
Band31 0.200206
Band32 0.375580
Band33 0.448510
Band34 0.515404
Band35 0.496416
Band36 0.509472
Band37 0.593171
Band38 1.052417
Band39 1.024995
Band40 0.984552
Band41 0.831029
Band42 0.785252
Band43 0.940512
Band44 1.303075
Band45 1.414533
Band46 1.772946
Band47 1.946918
Band48 1.324837
Band49 1.248168
Band50 1.504062
Band51 2.767722
Band52 1.998543
Band53 0.837772
Band54 1.177324
Band55 1.493668
Band56 1.088704
Band57 1.459808
Band58 1.592631
Band59 1.630487
Band60 2.880505
dtype: float64%matplotlib inline
df['Band4'].hist()
- 치우침을 제거했을 때의 성능 비교를 위한 모델 개발
# 라벨 숫자로 바꾸기
y_train.replace({'M':-1, 'R':1}, inplace=True)
y_test.replace({'M':-1, 'R':1}, inplace=True)# 원본 데이터로 모델링
from sklearn.neural_network import MLPClassifier as MLP
from sklearn.metrics import f1_score
model = MLP(random_state = 2313, max_iter = 1000)
model.fit(x_train, y_train)
pred_y = model.predict(x_test)
score = f1_score(y_test, pred_y)
print(score)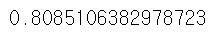
# 왜도 기반 치우친 변수 추출(왜도 절대값이 1.5 이상인 변수 추출)
import numpy as np
biased_variables = x_train.columns[x_train.skew().abs() > 1.5]
biased_variables
# 변수 치우침 제거
x_train[biased_variables] = x_train[biased_variables] - x_train[biased_variables].min() + 1
x_train[biased_variables] = np.log10(x_train[biased_variables])log를 취해도 되지만 상용로그(log10)을 취했다.
# 평가 데이터도 같은 방법으로 전처리 수행
x_test[biased_variables] = x_test[biased_variables] - x_test[biased_variables].min() + 1
x_test[biased_variables] = x_test[biased_variables].apply(np.log10)# 치우침 제거 후 모델 평가
model = MLP(random_state = 2313, max_iter = 1000).fit(x_train, y_train)
pred_y = model.predict(x_test)
score = f1_score(y_test, pred_y)
print(score)
변수 치우침을 제거 후 모델의 성능이 더 좋아졌음을 확인한다.